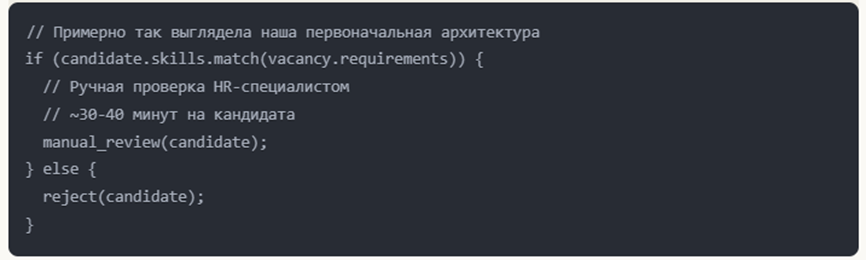
Когда O(n) мешает отбирать резюме в Росатоме
Главная проблема поиска сотрудников — предвзятость. Порой кажется, что наше резюме подходит под свою роль на 100 %, а рекрутер отклоняет его. Проблема с противоположной стороны баррикад: рекрутер должен отсмотреть по 200, 300 и более резюме в день. По разным данным, на каждое уходит всего лишь 6–10 секунд. А что если можно решить эти две проблемы с помощью ML? Сделать модель, которая исключит любой байес и поможет рекрутеру объективно отбирать подходящих кандидатов (где «подходящесть» обусловлена красивой математикой!). Мы это сделали. Оказалось, что если вы хотите добиться непредвзятости, то вам придётся внести в систему предвзятость. Оксюморон в статистике! Что мы увидели: Женатые и замужние — в топе: пока вы не уходите глубоко в анализ, этот быстрый фактор повышает ранг. Чем точнее ваша модель, тем меньше его вес. Английский — плохо: знание английского почему-то работало как антипаттерн, снижая релевантность. ОГУРЕЦ: кто-то зачем-то написал это слово в резюме. Оно попало в словарь модели и получило большой вес. Иксель — люди пишут Excel как угодно, и само слово в правильном написании оказалось снижающим оценку. К резюме может быть приложено много мусора. Самый эпичный пример: авиабилет Москва — Челябинск вместо резюме. Но давайте начну с начала.
https://habr.com/ru/companies/greenatom/articles/917546/
#автоматизация_бизнеспроцессов #анализ_данных #алгоритмы #искусственный_интеллект #hr #персонал #автоматизация #Bert #машинное_обучение #обучение_нейросетей #метрики #базы_данных