Krea (@krea_ai)
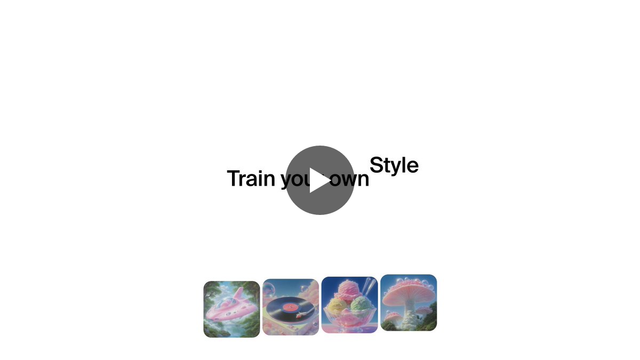
Krea 2에 LoRA 기반 파인튜닝 기능(beta)을 도입. 사용자가 자신의 스타일, 객체, 캐릭터에 맞춰 Krea 2를 정밀하게 학습시킬 수 있는 시스템으로, 이미지 생성/커스텀 모델 워크플로우에서 실무 활용성이 높은 업데이트다.
Krea (@krea_ai)
Krea 2에 LoRA 기반 파인튜닝 기능(beta)을 도입. 사용자가 자신의 스타일, 객체, 캐릭터에 맞춰 Krea 2를 정밀하게 학습시킬 수 있는 시스템으로, 이미지 생성/커스텀 모델 워크플로우에서 실무 활용성이 높은 업데이트다.
Akshay (@akshay_pachaar)
TransformerLab이 공개되었습니다. 어떤 클라우드의 GPU든 오케스트레이션해 사용자가 정의한 학습·평가 워크플로를 실행할 수 있는 오픈소스 플랫폼으로, LoRA/DPO/GRPO, MMLU, HellaSwag용 템플릿을 제공합니다. GUI, CLI, 에이전트 스킬로 사용할 수 있습니다.
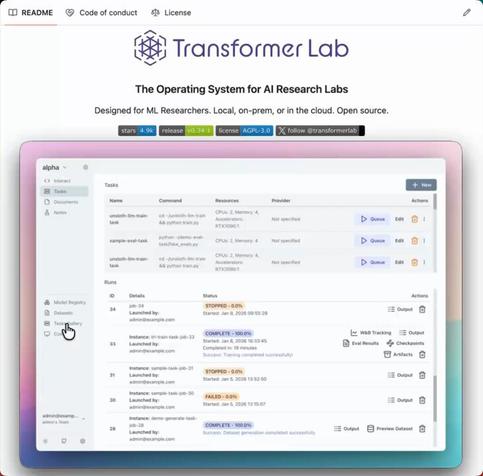
The Operating System for Al Research Labs. TransformerLab orchestrates GPUs across any cloud and runs any training or eval workflow you define Pre-built templates for LoRA, DPO, GRPO, MMLU, HellaSwag. Use it from a GUI, CLI, or agent skill. 100% open-source and FREE to use.
Brie Wensleydale (@SlipperyGem)
Kijai가 LTX 2.3 OmniNFT LoRA의 새 버전을 공개했다는 내용. LoRA 기반 확장 모델 업데이트로 보이며, LTX 계열 워크플로우를 사용하는 생성형 비디오/이미지 실무자들에게 참고할 만한 릴리스다.
🌞#Sun – The billion-year energy scandal!⚡
The #Zoomposium with Prof. Dr. #ThomasNaumann and Dr. #IljaBohnet focuses precisely on such fundamental #unansweredquestions in #science:
📎https://philosophies.de/index.php/2022/10/26/zoomposium-naumann-bohnet-das-raetselhafte-universum/
#NuclearFusion #Physics #Cosmology #Energy #Einstein #TheoryOfRelativity #OpenQuestions #DarkMatter #StringTheory #Metaphysics #DESY #PhilosophyOfScience #Universe #Cosmos #FineTuning #Research #Science #Philosophy #Astrophysics #NuclearPhysics
Conclusionpted-models" href="#revisiting-ai-governance-and-policy-for-adapted-models" class="toc-anchor">Revisiting AI Governance and Policy for Adapted Modelssafety-behavior-in-high-stakes-domains" href="#the-unpredictable-effects-of-model-modifications-on-safety-behavior-in-high-stakes-domains" class="toc-anchor">The unpredictable effects of model modifications on safety behavior in high-stakes domainsof-model-modification-for-ai-supply-chain-governance" href="#the-challenge-of-model-modification-for-ai-supply-chain-governance" class="toc-anchor">The Challenge of Model Modification for AI Supply Chain Governancef the Algorithmic Alignment Group at the Massachusetts Institute of Technology (MIT). [ Read full report ] General-purpose AI models are increasingly […]
RT @jun_song: One of my best friends from my US college days works as an AI engineer at Big Tech and is about to finish his PhD. I only got my bachelor's, came back to Korea, and worked in a completely different field: strategic planning. My job was planning new businesses and making factories and affiliates run efficiently. My only involvement with AI was building and implementing workflow automation when they asked for it. I was talking to my friend recently. He knows everything about his specific field, but he knew absolutely nothing about how local LLMs work or post-training. That made me realize something: AI has so many different subfields, and having a degree doesn’t mean you know everything. Curiosity for new things and the drive to learn them will be way more important than a degree going forward. And I’ve said this before, but I’m not posting this motivation to sell you a course. I will never do that. Set up a research multi-agent for the latest information and study new things. It will help you massively. If you can leverage your current domain knowledge to figure out which fields will be promising in the future, that’s the best scenario. Thanks for reading this long post. I genuinely want all my followers to succeed, and I hope this information was helpful. 송준 Jun Song (@jun_song) A year ago, I didn't care about fine-tuning or post-training at all. But when I thought about corporate security, it hit me: the demand for fine-tuning is going to be massive. I locked in for a few months. Using nothing but my MacBook, I fine-tuned the SuperGemma4 series entirely on my own, and it r…
mehr auf Arint.info
#agent #finetuning #Huggingface #nitter #opensource #things #US #arint_info
<p>RT @jun_song: One of my best friends from my US college days works as an AI engineer at Big Tech and is about to finish his PhD. I only got my bachelor's, came back to Korea, and worked in a completely different field: strategic planning. My job was planning new businesses and making factories and affiliates run efficiently. My only involvement with AI was building and implementing workflow automation when they asked for it. I was talking to my friend recently. He knows everything about his specific field, but he knew absolutely nothing about how local LLMs work or post-training. That made me realize something: AI has so many different subfields, and having a degree doesn’t mean you know everything. Curiosity for new things and the drive to learn them will be way more important than a degree going forward. And I’ve said this before, but I’m not posting this motivation to sell you a course. I will never do that. Set up a research multi-agent for the latest information and study new things. It will help you massively. If you can leverage your current domain knowledge to figure out which fields will be promising in the future, that’s the best scenario. Thanks for reading this long post. I genuinely want all my followers to succeed, and I hope this information was helpful. 송준 Jun Song (@jun_song) A year ago, I didn't care about fine-tuning or post-training at all. But when I thought about corporate security, it hit me: the demand for fine-tuning is going to be massive. I locked in for a few months. Using nothing but my MacBook, I fine-tuned the SuperGemma4 series entirely on my own, and it r…</p> <p><a href="https://arint.info/@Arint/116600661987139175">mehr</a> auf <a href="https://arint.info/">Arint.info</a></p> <p>#agent #finetuning #Huggingface #nitter #opensource #things #US #arint_info</p> <p><a href="https://x.com/jun_song/status/2056591055064318143#m">https://x.com/jun_song/status/2056591055064318143#m</a></p>
Forge LM (@ForgeLm67197)
분류(classification) 작업이 파인튜닝 ROI가 가장 높은 영역 중 하나라고 언급하며, ForgeLM이 이 워크플로를 단순화한다고 소개합니다. 단일 YAML로 SFT를 설정하고, 데이터 자동 검증과 함께 Ollama/vLLM으로 직접 배포할 수 있어 초보자용 마법사와 고급 사용자용 풀 설정을 모두 지원합니다.

@rasbt Classification is where most fine-tuning ROI lives—boring but lucrative. ForgeLM optimizes this workflow: one YAML for SFT, auto data validation, and direct deploy to Ollama/vLLM. Wizard for beginners, full config for power users: https://t.co/OpwYTWy8Ot
RAG vs. Fine-Tuning – The Question Every AI Builder Gets Wrong
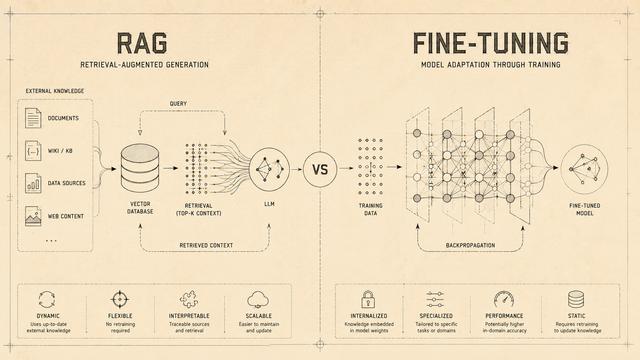
이 글은 AI 개발자들이 자주 오해하는 RAG(검색 증강 생성)와 파인튜닝의 차이를 명확히 설명한다. 파인튜닝은 모델 내부에 도메인 특화 행동과 지식을 내장하는 방식으로, 특정 분야의 일관된 행동과 추론에 적합하다. 반면 RAG는 외부 지식베이스에서 실시간으로 정보를 검색해 최신성과 투명성을 확보하며, 대부분 기업용 고객 지원과 문서 질의응답에 적합하다. 2026년에는 이 둘을 조율하는 에이전트 기반 시스템이 부상하며, AI 서비스 구축 시 세 가지 접근법을 모두 이해하는 것이 중요하다.
Dwarkesh Patel (@dwarkesh_sp)
카파르티의 코멘트를 인용하며, 지속학습을 '가중치와 컨텍스트의 경계를 없애는 것'으로 보는 관점에 반박합니다. 인간은 그런 방식이 아니라, 작업 기억은 지워지고 장기 기억은 더 안정적으로 유지된다는 점을 상기시키며 연속 학습 설계에 시사점을 줍니다.

Continual learning sometimes gets discussed as if the goal is to dissolve the context/weights distinction. Let the model just keep accumulating, fine-tuning itself on the fly. @karpathy points out, though, that this isn't how humans do it. Our working memory gets wiped
Gorden Sun (@Gorden_Sun)
단일 주석 비디오로 가벼운 LoRA 파인튜닝만 수행해, 입력된 시점과 카메라 워크를 따르는 인터랙티브 비디오 생성을 구현한 연구를 소개. 적은 데이터로 비디오 생성 모델을 조건 제어하는 접근으로, 비디오 생성/편집 분야에서 흥미로운 초기 결과.