Контекст — не инфраструктура: почему большое окно не заменяет retrieval-слой
Зачем строить RAG или retrieval-слой, если современные модели уже умеют работать с огромным контекстом?
Контекст — не инфраструктура: почему большое окно не заменяет retrieval-слой
Зачем строить RAG или retrieval-слой, если современные модели уже умеют работать с огромным контекстом?
دليل IBM الجديد "RAG Cookbook" يشرح كيف نبني أنظمة استرجاع معتمد على نماذج اللغة الكبيرة.
🔹 **مفتاح النجاح:** دمج محرك بحث محلي مع نموذج LLM يرفع دقة النتائج ويقلل زمن الاستجابة، مع الحفاظ على سرية البيانات.
🔹 مثال عملي: تخزين embeddings محليًا ثم طلب توليد إجابات من نموذج AI فقط عند الحاجة.
"Reading Between the Citations: A Typed Claim Network for Scientific Literature"
We propose the claim network: a representational pattern in which each cross-document reference is reified as a typed claim, carrying source, target, claim text, and a four-class stance label grounded in the citation-intent literature. This is a way of improving the performance of RAG systems.
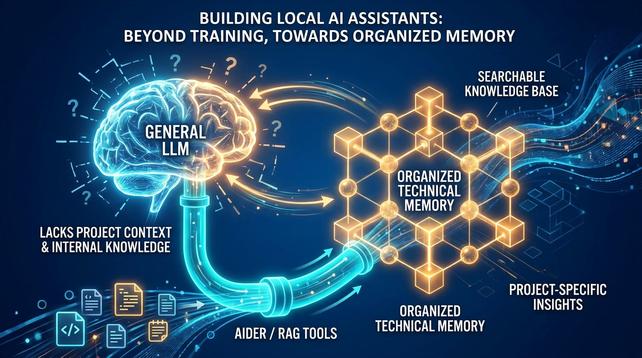
축적된 Ruby 지식을 로컬 코딩 어시스턴트로 전환하는 방법
범용 LLM은 Ruby의 일반적인 문법을 잘 알고 있지만, 특정 프로젝트의 관습이나 내부 라이브러리, 비공개 코드베이스에 대한 맥락이 부족하다는 한계가 있다.
教育プラットフォームを Next.js 16 + Supabase Pro で本番運用している話 — 40 名同時アクセス対応 / RAG / PWA / 多テナント
https://qiita.com/TaichiEndoh/items/ea57c1a2b9d6b321279b?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items
AI для PHP-разработчиков. Часть 7: Экосистема AI-агентов в PHP – от простых вызовов OpenAI до мультиагентных платформ
За последние два года в экосистеме PHP вокруг AI-разработки сформировалась целая индустрия. Если раньше интеграция LLM выглядела как несколько строк кода с вызовом OpenAI API, то сегодня разработчики строят полноценные агентные системы: с памятью, инструментами, workflow, наблюдаемостью (observability) и даже командами специализированных агентов. Обычно, когда говорят об AI-разработке, в первую очередь говорят о Python. Тут полно интересных вещей, таких как: LangChain, LangGraph, CrewAI, AutoGen – весь основной шум долгое время происходил именно там. Но параллельно интересная история развивается и в PHP. И меня это, безусловно, очень радует. Причем если еще пару лет назад PHP-разработчику приходилось буквально собирать все вручную поверх SDK провайдеров, то сегодня уже существует полноценная экосистема инструментов разного уровня абстракции – от клиентов для работы с моделями до платформ управления многоагентными системами. Давайте посмотрим, как выглядит этот рынок сейчас.
https://habr.com/ru/articles/1041594/
#php #ииагенты #LLM #OpenAI #MultiAgent_Systems #Prism_PHP #Laravel_AI #Neuron_AI #RAG #Structured_Output

Это седьмая часть проекта. Часть 6: Bag of Words и TF–IDF – как компьютер превращает текст в математику Часть 5: От массивов к GPU: как PHP-экосистема приходит к настоящему ML Часть...



 Qiita - 人気の記事
Qiita - 人気の記事