Self-Distillation
Discover how self-distillation enables continual learning with minimal overhead

Self-Distillation
Discover how self-distillation enables continual learning with minimal overhead
Dwarkesh Patel (@dwarkesh_sp)
카파르티의 코멘트를 인용하며, 지속학습을 '가중치와 컨텍스트의 경계를 없애는 것'으로 보는 관점에 반박합니다. 인간은 그런 방식이 아니라, 작업 기억은 지워지고 장기 기억은 더 안정적으로 유지된다는 점을 상기시키며 연속 학습 설계에 시사점을 줍니다.

Continual learning sometimes gets discussed as if the goal is to dissolve the context/weights distinction. Let the model just keep accumulating, fine-tuning itself on the fly. @karpathy points out, though, that this isn't how humans do it. Our working memory gets wiped
Self-Distillation Enables Continual Learning [PDF]
https://arxiv.org/abs/2601.19897
#HackerNews #SelfDistillation #ContinualLearning #MachineLearning #AIResearch #PDF

Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.
Useful Memories Become Faulty When Continuously Updated by LLMs
최근 연구는 LLM 에이전트가 문제 해결 경험을 텍스트로 요약해 메모리에 저장하고 재사용하는 방식이 지속적 자기개선에 실패할 수 있음을 보여준다. GPT-5.4는 ARC-AGI 문제를 메모리 없이 100% 해결했으나, 동일 문제를 메모리 기반으로 재처리하면 정확도가 54%로 급락했다. 문제는 데이터가 아니라 메모리 재작성 과정에서 발생하며, 과도한 추상화와 잘못된 통합이 기억 왜곡을 초래한다. 에피소드별 원본 증거를 선별적으로 유지하는 방식이 더 안정적인 성능을 보였다. 이는 LLM 기반 지속학습 설계에 있어 메모리 통합 전략의 근본적 재고가 필요함을 시사한다.
Show HN: RVW – A transformer model capable of online continual learning
RVW는 사전학습된 트랜스포머 모델을 온라인으로 지속 학습할 수 있게 설계된 새로운 아키텍처입니다. 각 레이어별 전문가 집단을 동적으로 확장 및 축소하며, 리플레이 버퍼나 명시적 태스크 식별자 없이 분포 변화에 적응합니다. TinyLlama-1.1B에 적용 시 기존 EWC, 파인튜닝, LoRA 대비 훨씬 낮은 퍼플렉서티를 기록하며 이전 도메인 성능도 유지합니다. 도메인 지식은 개별 전문가보다 레이어 간 라우팅 패턴에 의해 인코딩되는 것으로 보입니다.
https://zenodo.org/records/20064618
#continuallearning #transformer #onlinelearning #lora #tinyllama
Inspired by the role of sleep in biological continual learning, we introduce RVW, a trans- former architecture for online continual adaptation of pretrained models. RVW maintains a small pool of per-layer experts that grow and prune in response to distribution shift, with no replay buffer and no explicit task identifier. Applied to TinyLlama-1.1B on a 15,000- chunk six-domain stream, RVW reaches 40 average held-out PPL, substantially better than EWC (158), fine-tuning (164), and LoRA (448) on the same parameter-matched base, while preserving prior-domain performance. Threshold sweeps suggest a combinatorial encoding reading: domain knowledge appears to be carried by routing patterns across layers rather than by individual specialized experts.
Our partners from CeADAR Ireland published a new paper on Continual Learning in the #CloudEdgeIoT Continuum. It explores how adaptive #AI can address concept drift, dynamic data & resource constraints.
This is key for enabling efficient, trustworthy AI & MetaOS orchestration across @O_CEI_Horizon ecosystem.
📑 Read the paper: https://o-cei.eu/wp-content/uploads/2026/03/Paper-CeADAR-Jan-2026-ICP.000586-3-2.pdf
📰 Discover O-CEI publications: https://o-cei.eu/scientific-publications/

AI 에이전트가 스스로 진화하는 3가지 방식, 모델 교체만이 답이 아니다
AI 에이전트의 학습은 모델 업데이트만이 아닙니다. LangChain이 제시한 모델·하네스·컨텍스트 3레이어 프레임워크를 소개합니다.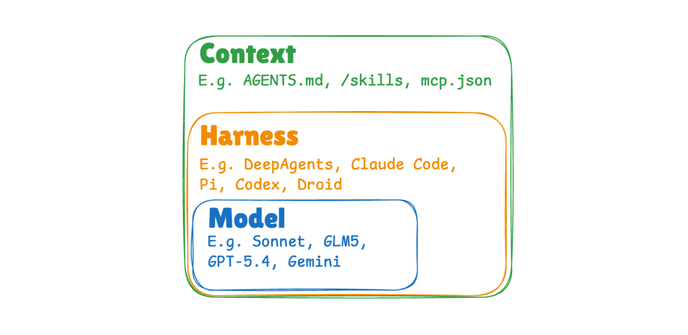
fly51fly (@fly51fly)
Google Research와 University of Wisconsin-Madison 공동 저자들의 2026년 논문 'Grow, Don't Overwrite: Fine-tuning Without Forgetting'(arXiv)이 공유되었습니다. 미세조정(fine-tuning) 시 기존 지식을 잃지 않도록 하는 방법을 제안하는 연구로, 모델 지속 학습과 캐타스트로픽 포게팅 문제에 대한 해결책을 다룹니다. arXiv 링크 포함.
Awni Hannun (@awnihannun)
장기 실행 에이전트와 관련된 지속학습에 대한 관찰과 소규모 실험 보고. MLX로 토이 실험을 해본 결과, 프롬프트 압축(prompt compaction)과 재귀적 서브에이전트(recursive sub-agents)를 결합한 현재의 접근법이 의외로 효과적이며 장기 에이전트 설계에 유용할 수 있다는 판단을 제시함.

I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX). The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go
