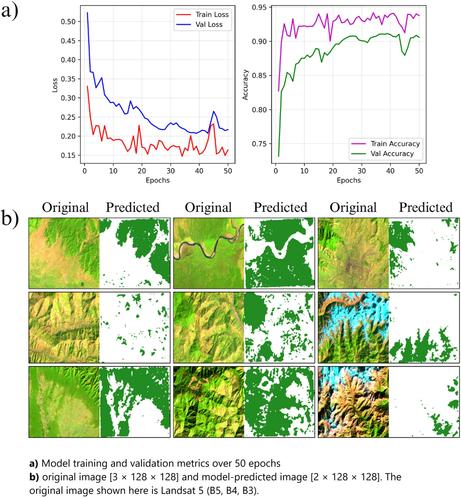
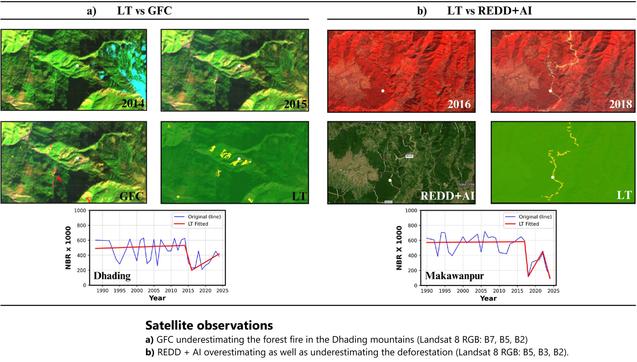
Я выяснил, что Яндекс Музыка на треть состоит из нейрослопа
Возможно вы уже знаете, что в чарт «Яндекс Музыки» залетают треки, сгенерированные ИИ. Например, перепевка стихотворения Есенина «Сыпь, гармоника», которая сейчас на 16 месте чарта. Или трек «Ярмарка судеб» исполнителя Alena, который был даже спет в эфире телеканала Россия 1 . Мне нравились алгоритмы «Яндекс Музыки». Благодаря им в своё время я открыл много малоизвестных артистов, которых слушаю до сих пор. Но с появлением Suno, Lyria, Udio, алгоритмами рекомендаций Яндекса пользоваться стало невозможно. Мне то и дело подсовывались низкокачественные ИИ-треки. В какой-то момент меня это достало. Я провёл своё расследование и получил неутешительные результаты. В базе «Яндекс Музыки» сейчас как минимум 77 тысяч ИИ-исполнителей . Ежемесячно они загружают от 100 тысяч ИИ-треков , что составляет примерно треть от всех загружаемых треков. А каждый 10-й трек в чарте – сгенерирован ИИ . И «Яндекс» ничего с этим не делает. Читать результаты расследования
https://habr.com/ru/articles/1036166/
#ии #нейросети #музыка #машинное_обучение #xgboost #расширения_браузеров #python #typescript