Caddy compatibility for zeroserve: 3x throughput and 70% lower latency
https://su3.io/posts/zeroserve-caddy-compat
#HackerNews #Caddy #Zeroserve #Throughput #Latency #Compatibility
Caddy compatibility for zeroserve: 3x throughput and 70% lower latency
https://su3.io/posts/zeroserve-caddy-compat
#HackerNews #Caddy #Zeroserve #Throughput #Latency #Compatibility
RT @HotAisle: Kimi K2.6 + DFlash: 508 tok/s auf 8x H100
mehr auf Arint.info
#inference #LLM #LLMServing #throughput #transformers #arint_info
<p>RT @HotAisle: Kimi K2.6 + DFlash: 508 tok/s auf 8x H100</p> <p><a href="https://arint.info/@Arint/116447493456384838">mehr</a> auf <a href="https://arint.info/">Arint.info</a></p> <p>#inference #LLM #LLMServing #throughput #transformers #arint_info</p> <p><a href="https://x.com/HotAisle/status/2046620289984057634#m">https://x.com/HotAisle/status/2046620289984057634#m</a></p>
Как одна буква в ассемблере стоит 3× производительности
Я хочу показать вам, как одна буква в ассемблере может стоить 3× производительности. Не в теории — на живых замерах. По дороге мы заглянем внутрь процессора: Register Alias Table, partial register merge, scheduler, latency vs throughput, и даже обнаружим, что делитель выдаёт остаток раньше частного. Но начнём с основ. Приготовьтесь: кроличья нора окажется глубже, чем кажется.
https://habr.com/ru/articles/1024862/?utm_source=habrahabr&utm_medium=rss&utm_campaign=1024862
#x86 #assembly #NASM #div #partial_register_merge #latency #throughput #микроархитектура #Skylake #оптимизация
Как одна буква в ассемблере стоит 3× производительности
Я хочу показать вам, как одна буква в ассемблере может стоить 3× производительности. Не в теории — на живых замерах. По дороге мы заглянем внутрь процессора: Register Alias Table, partial register merge, scheduler, latency vs throughput, и даже обнаружим, что делитель выдаёт остаток раньше частного. Но начнём с основ. Приготовьтесь: кроличья нора окажется глубже, чем кажется.
https://habr.com/ru/articles/1024862/
#x86 #assembly #NASM #div #partial_register_merge #latency #throughput #микроархитектура #Skylake #оптимизация
We have an onboarding guide:
Your First Dataset from #Jira, #Trello, or #OpenProject
It shows how easy it is to get your data from those systems. Just follow these simple steps and analyze your data!
#Cylenivo #Agile #CycleTime #LeadTime #Throughput #Flow #Scrum #Kanban

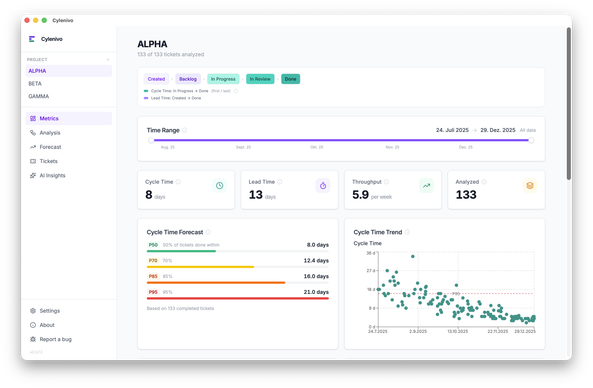
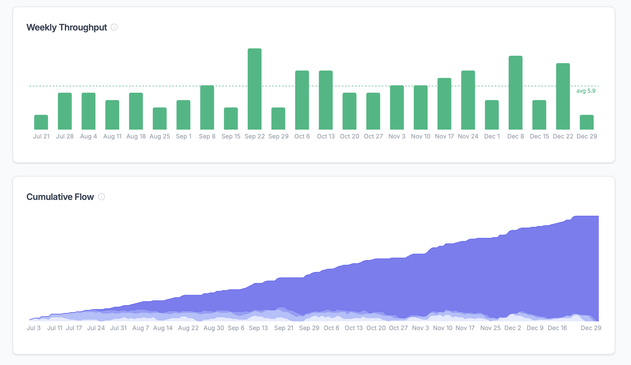
If you want a precise measure of your Cycle Time, Lead Time, and Throughput on your local machine, maybe you want to check out #Cylenivo - a free App for Windows, Linux, and Mac. Connect to Jira (or Trello or OpenProject), download your Ticket data, and analyze. Give it a try - it's free and Open Source. And boost if you like it!
#Jira #Trello #OpenProject #CycleTime #LeadTime #Throughput #App #FOSS
Jira tells you your tickets exist. It won't tell you how fast your team actually learns. So I built Cylenivo: cycle time, lead time, throughput, and Monte Carlo delivery forecasts, pulled straight from your Jira data.
Fully local. No cloud. Open Source.
This is my passion project! I'd love to hear what flow metrics matter most to your team.
Beta is live: https://cylenivo.org/
Boosts are very welcome!
#agile #cycletime #leadtime #throughput #kanban #scrum #flowmetrics #foss #jira
@catsalad ha! You slay me.
#humor #buffy #slayer #vampire #buffering #throughput #latency