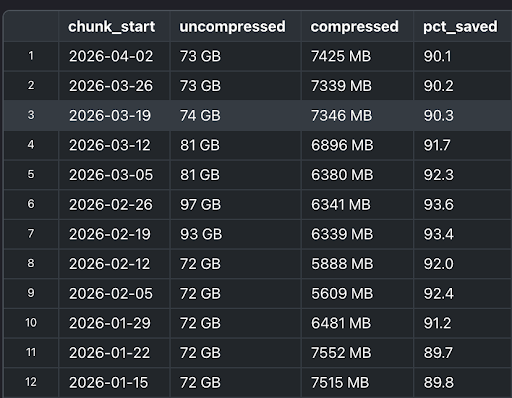
Архитектура высоконагруженных RAG-систем: 10 стратегий оптимизации чанкинга и интеграция с Weaviate, Qwen / Llama /Gemma
Привет, Хабр! Это Андрей Носов, AI-архитектор в компании Raft, проектирую и внедряю высоконагруженные RAG-системы на предприятиях. Сегодня я расскажу о вызовах, которые мы преодолеваем каждый день, создавая такие системы, и сделаю акцент на чанкинге. Обозначим направления, в которых мы будем работать. Сегодня поговорим только о двух возможностях применения больших языковых моделей — это MedTech и LegalTech. Они наиболее востребованные на рынке в текущий момент в плане систем поиска. Такой выбор направлений связан с глобальным трендом на работу с профессиональными знаниями, о котором говорят Gartner и OpenAI.
https://habr.com/ru/companies/oleg-bunin/articles/967102/
#rag #chunking #llm #genai #архитектура #чанкинг #highload #highload++