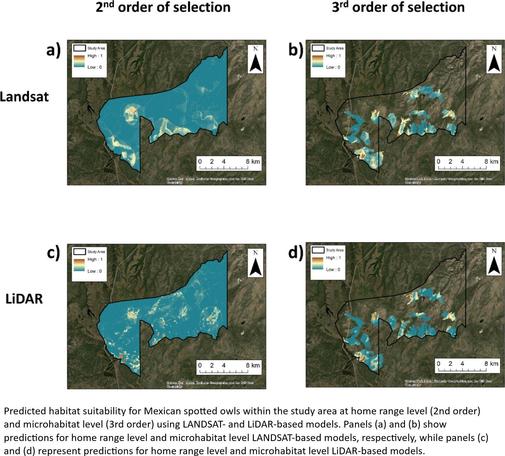
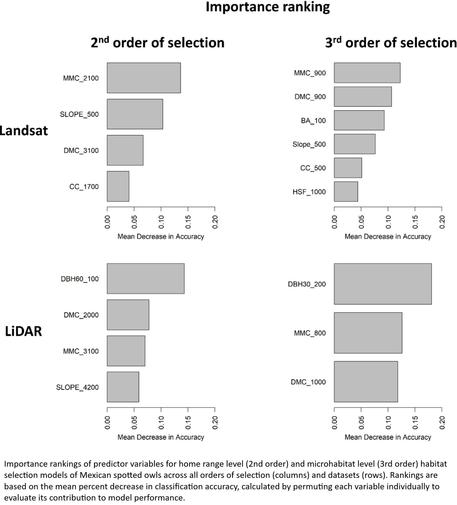
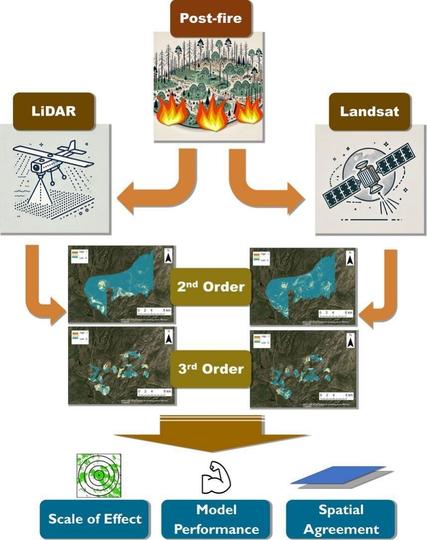
A Multi-Level, Multi-Scale Comparison Of Lidar- And LANDSAT-Based Habitat Selection Models Of Mexican Spotted Owls In A Post-Fire Landscape
--
https://doi.org/10.1016/j.ecoinf.2025.103168 <-- shared paper
--
#GIS #spatial #mapping #Habitat #suitability #Megafire #Scaling #Habitatsuitability #selection #model #modeling #framework #Strixoccidentalis #Wildfire #bushfire #remotesening #LIDAR #elevation #ecosystem #LANDSAT #comparasion #mexican #spottedowl #avian #postfire #landscape #vegetation #ecosystem #damage #risk #hazard #earthobservation #scaling #scale #multifactor #homerange #microhabitat #ecology #recovery #spatialanalysis #spatiotemporal #modelperformance #reliability #accuracy #precision #forest #integration #conservation #landscape #fireaffected #spatialdisagreement
--
https://doi.org/10.1016/j.ecoinf.2025.103168 <-- shared paper
--
#GIS #spatial #mapping #Habitat #suitability #Megafire #Scaling #Habitatsuitability #selection #model #modeling #framework #Strixoccidentalis #Wildfire #bushfire #remotesening #LIDAR #elevation #ecosystem #LANDSAT #comparasion #mexican #spottedowl #avian #postfire #landscape #vegetation #ecosystem #damage #risk #hazard #earthobservation #scaling #scale #multifactor #homerange #microhabitat #ecology #recovery #spatialanalysis #spatiotemporal #modelperformance #reliability #accuracy #precision #forest #integration #conservation #landscape #fireaffected #spatialdisagreement