fly51fly (@fly51fly)
UC Berkeley와 Allen Institute for AI 연구진이 Mixture of Experts의 사전학습을 통해 emergent modularity를 유도하는 EMO를 제안했다. 이 연구는 MoE 모델의 구조적 모듈성이 어떻게 자연스럽게 형성되는지 다루는 최신 AI 연구로, 대규모 모델 설계와 효율적 학습에 중요한 시사점을 준다.
fly51fly (@fly51fly)
UC Berkeley와 Allen Institute for AI 연구진이 Mixture of Experts의 사전학습을 통해 emergent modularity를 유도하는 EMO를 제안했다. 이 연구는 MoE 모델의 구조적 모듈성이 어떻게 자연스럽게 형성되는지 다루는 최신 AI 연구로, 대규모 모델 설계와 효율적 학습에 중요한 시사점을 준다.
UniPool: A Globally Shared Expert Pool for Mixture-of-Experts
UniPool은 기존 Mixture-of-Experts(MoE) 아키텍처의 각 층별 독립 전문가 집합 방식을 전역 공유 전문가 풀로 대체한 새로운 MoE 구조입니다. 이를 통해 전문가 파라미터가 층 깊이에 선형적으로 증가할 필요 없이, 공유 풀 내에서 효율적이고 안정적인 라우팅과 균형 잡힌 전문가 활용을 가능하게 합니다. LLaMA 기반 다양한 모델 크기에서 UniPool은 기존 MoE 대비 검증 손실과 혼란도를 일관되게 개선하며, 전문가 파라미터 예산을 줄이면서도 성능을 유지하거나 향상시켰습니다. 이 연구는 MoE의 깊이 확장과 전문가 파라미터 할당에 대한 새로운 설계 방향을 제시합니다.

Modern Mixture-of-Experts (MoE) architectures allocate expert capacity through a rigid per-layer rule: each transformer layer owns a separate expert set. This convention couples depth scaling with linear expert-parameter growth and assumes that every layer needs isolated expert capacity. However, recent analyses and our routing probe challenge this allocation rule: replacing a deeper layer's learned top-k router with uniform random routing drops downstream accuracy by only 1.0-1.6 points across multiple production MoE models. Motivated by this redundancy, we propose UniPool, an MoE architecture that treats expert capacity as a global architectural budget by replacing per-layer expert ownership with a single shared pool accessed by independent per-layer routers. To enable stable and balanced training under sharing, we introduce a pool-level auxiliary loss that balances expert utilization across the entire pool, and adopt NormRouter to provide sparse and scale-stable routing into the shared expert pool. Across five LLaMA-architecture model scales (182M, 469M, 650M, 830M, and 978M parameters) trained on 30B tokens from the Pile, UniPool consistently improves validation loss and perplexity over the matched vanilla MoE baselines. Across these scales, UniPool reduces validation loss by up to 0.0386 relative to vanilla MoE. Beyond raw loss improvement, our results identify pool size as an explicit depth-scaling hyperparameter: reduced-pool UniPool variants using only 41.6%-66.7% of the vanilla expert-parameter budget match or outperform layer-wise MoE at the tested scales. This shows that, under a shared-pool design, expert parameters need not grow linearly with depth; they can grow sublinearly while remaining more efficient and effective than vanilla MoE. Further analysis shows that UniPool's benefits compose with finer-grained expert decomposition.
Some cool work from allen institute where they trained a more understandable mixture of experts model. The content that the experts are experts at are more clustered and better resemble human topics. A big benefit of this is it looks like you can remove an expert from the model and performance degrades much more gracefully than a standard MoE.
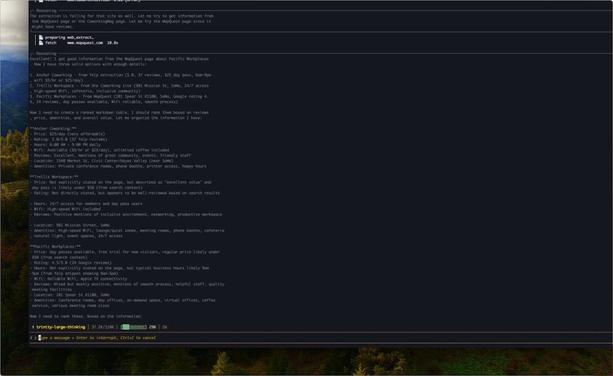
Arcee Trinity Large Technical Report
Arcee Trinity Large는 4000억 개의 파라미터를 가진 희소 Mixture-of-Experts(MoE) 모델로, 토큰당 130억 개의 활성화 파라미터를 사용한다. 이와 함께 Trinity Nano(60억 파라미터)와 Trinity Mini(260억 파라미터) 모델도 소개되었으며, 모두 최신 아키텍처와 새로운 MoE 부하 균형 전략인 SMEBU를 적용했다. 모델들은 Muon 옵티마이저로 훈련되었고, 대규모 토큰 데이터셋(최대 170억 토큰)으로 사전학습되었다. 이 기술 보고서는 대규모 희소 모델 설계와 훈련에 중요한 참고자료가 될 전망이다.
https://arxiv.org/abs/2602.17004
#machinelearning #mixtureofexperts #largescale #transformers #optimization

We present the technical report for Arcee Trinity Large, a sparse Mixture-of-Experts model with 400B total parameters and 13B activated per token. Additionally, we report on Trinity Nano and Trinity Mini, with Trinity Nano having 6B total parameters with 1B activated per token, Trinity Mini having 26B total parameters with 3B activated per token. The models' modern architecture includes interleaved local and global attention, gated attention, depth-scaled sandwich norm, and sigmoid routing for Mixture-of-Experts. For Trinity Large, we also introduce a new MoE load balancing strategy titled Soft-clamped Momentum Expert Bias Updates (SMEBU). We train the models using the Muon optimizer. All three models completed training with zero loss spikes. Trinity Nano and Trinity Mini were pre-trained on 10 trillion tokens, and Trinity Large was pre-trained on 17 trillion tokens. The model checkpoints are available at https://huggingface.co/arcee-ai.
https://winbuzzer.com/2026/04/27/deepseek-v4-open-weights-launch-xcxwbn/
DeepSeek V4 Ships 1M Context, Open-Weights
#AI #DeepSeekV4 #DeepSeek #OpenSourceAI #AIModels #MixtureOfExperts #ChinaAI #GenerativeAI #EnterpriseAI

Design Arena (@Designarena)
withnucleusai의 Nucleus-Image가 Design Arena에 추가되었습니다. 이 모델은 파라미터 효율적인 Mixture-of-Experts 이미지 모델로, 프롬프트 이해력이 뛰어나고 공간 배치도 정밀하게 처리하는 것이 특징입니다.
https://x.com/Designarena/status/2044873593574818108
#imagegeneration #mixtureofexperts #aivisual #model #designarena
https://winbuzzer.com/2026/04/03/arcee-ai-399b-open-source-reasoning-model-apache-2-xcxwbn/
Arcee AI Launches 399B Top-Performing Open-Source Model at 96% Lower Cost
#AI #ArceeAI #OpenSourceAI #LLMs #AIModels #MixtureOfExperts
Gemma 4: Google's Most Capable Open Models Are Here — and They Run on Your Laptop
https://techlife.blog/posts/gemma-4-google-open-models
#Gemma4 #GoogleAI #OpenSourceAI #LLM #OnDeviceAI #MixtureOfExperts

Google's Gemma 4 family brings frontier-level AI reasoning to devices ranging from Android phones to developer workstations, under a fully open Apache 2.0 license.
Simon Willison (@simonw)
거대한 Mixture-of-Experts 모델도 Mac 하드웨어에서 전체를 RAM에 올리지 않고 SSD에서 전문가 가중치를 일부씩 스트리밍해 실행할 수 있다는 점을 소개한다. Kimi 2.5는 1T 파라미터지만 활성화되는 32B만 필요해 96GB 메모리에서 구동 가능하다고 언급한다.

Turns out you can run enormous Mixture-of-Experts on Mac hardware without fitting the whole model in RAM by streaming a subset of expert weights from SSD for each generated token - and people keep finding ways to run bigger models Kimi 2.5 is 1T, but only 32B active so fits 96GB
Nemotron 3 Super pushes the frontier with 40 M supervised & alignment samples, leveraging a Mamba‑Transformer backbone and Mixture‑of‑Experts scaling. The model shows stronger agent reasoning, RL‑based fine‑tuning, and tighter AI alignment. Dive into the details to see how this LLM reshapes open‑source AI. #Nemotron3 #MixtureOfExperts #AIAlignment #SupervisedFineTuning
🔗 https://aidailypost.com/news/nemotron-3-super-incorporates-40-million-supervised-alignment-samples



