Interesting video on LLM clustering with Exo by EXO Labs.

Interesting video on LLM clustering with Exo by EXO Labs.
Kevin Simback (@KSimback)
홈 실험용으로 작은 AI 모델들을 실행할 수 있고, exolabs를 통해 여러 모델을 연결할 수 있다고 소개합니다. 개인 환경에서 경량 모델을 활용해 여러 모델을 묶는 실험적 AI 사용 사례를 제시합니다.
Scooby Snackz (@NotScoobySnackz)
로컬 네트워크의 여러 기기와 연결해 분산 추론을 수행하는 아이디어가 언급됐다. @exolabs를 활용한 임시 Wi‑Fi 기반 분산 inference 가능성을 제시하며, 경량 네트워크 환경에서의 새로운 AI 실행 방식에 대한 흥미로운 가능성을 보여준다.

@googlegemma This also in theory means such a jerryrigged app could connect to other devices on the local network and run distributed inference via @exolabs over ad hoc wifi Again, not saying this would be optimal or a useful tps, but with a strong enough wireless connection and a small
Paul (@paulyoung)
macOS와 Linux 간 연동을 성공시킨 뒤 모델을 로드할 준비를 하고 있다는 내용입니다. Exolabs를 이용한 이기종 시스템 연결과 로컬 모델 실행 환경 구축 흐름을 보여주는 짧은 업데이트입니다.
Peter Corbett (@corbett3000)
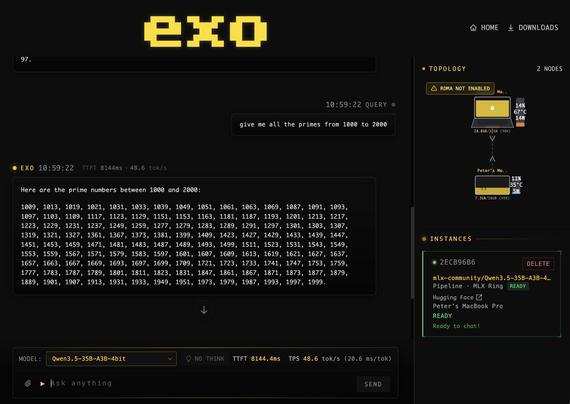
Exolabs와 M5, Mac mini M3 조합으로 Qwen3.5-35B-A3B-4B를 로컬 실행해 48.6 tok/s 성능을 확인한 사용기입니다. RDMA는 아직 없지만, 로컬 LLM 환경에서 애플 실리콘 기반 멀티 디바이스 추론 성능과 exolabs 활용 가능성을 보여줍니다.
William Ruider (@ruider92545)
EXO Labs 1.0.69이 2022년형 6노드 Mac M1 Studio Max 클러스터에서 Thunderbolt 4와 MLX ring만으로 대형 모델 Qwen3.5-122B-A10B(8-bit/FP8, 131GB)를 구동하는 놀라운 성능을 보여줬다는 내용이다. 로컬 분산 추론/실행 성능의 큰 진전을 암시한다.
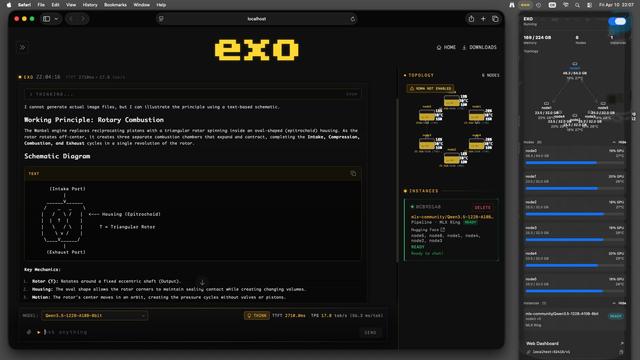
Guys and Girls, look >>> what EXO Labs 1.0.69 did to my 6-node Mac M1 Studio Max cluster (from 2022) over Thunderbolt 4 without RDMA, MLX ring. Just downloaded Qwen3.5-122B-A10B (8-bit/FP8) MLX 131 GB heavy. Thinking mode I have a …. WHAT!!!! No way!!!! Am I dreaming ???!
Aibra (@aibra)
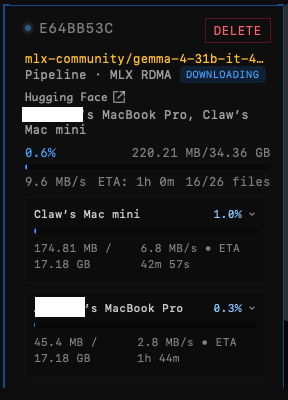
집에 있는 기존 기기만으로 로컬 환경에서 Gemma 4 31B를 실행할 수 있게 되었다는 내용입니다. Exo(@exolabs)를 활용해 고성능 대형 모델을 로컬에서 돌리는 실험이 가능해졌다는 점이 핵심이며, 로컬 AI 추론과 분산 실행 활용 가능성을 보여줍니다.
Alex Cheema (@alexocheema)
4년 된 M1 Max Mac Studio 6대를 재활용해 MiniMax AI의 M2.5를 Exo Labs로 실행하는 사례가 공유됐다. 중고 장비와 높은 메모리 대역폭을 활용해 저비용으로 대규모 AI 클러스터를 구성할 수 있음을 보여준다.
Alex Cheema (@alexocheema)
M1 Max Mac Studio 6대로 구성한 홈 클러스터에서 MiniMax AI의 M2.5 모델을 Exo Labs와 Thunderbolt 4 인터커넥트로 구동하는 사례가 공유됐다. 다양한 AI 홈랩 구성과 이기종 저비용 추론 환경의 가능성을 보여준다.
Alex Cheema (@alexocheema)
베이징의 한 학교가 기존의 구형 Mac을 재활용해 Exolabs를 이용, 100% 로컬에서 동작하는 개인화 AI 에이전트를 운영하고 있다는 사례입니다. 해당 Mac들은 원래 영화·영상 편집용으로 쓰였으며 학교 데이터 전체를 흡수시켜 로컬 에이전트를 구동하는 교육적 적용 사례로 소개됩니다.

China is way ahead on AI adoption. A school in Beijing has repurposed old macs to run personalised AI agents 100% locally using @exolabs The macs were previously used in their film studies lab, for video editing. They have ingested their entire corpus of school data: