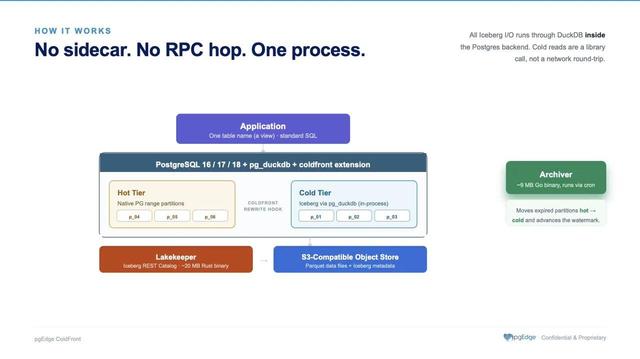
Retour d’expérience : *comment sauver un projet Data*. #DataEngineering #RetourExpérience #Expertise #Tech #Luxe ... https://www.linkedin.com/posts/gabriel-chandesris_dataengineering-retourexpaezrience-expertise-share-7475449675840630784-njtJ/

#dataengineering #retourexpérience #expertise #tech #luxe | Gabriel.. C.
Un projet Data en crise ? Voici comment je l’ai *sauvé* : - *Diagnostic* : Identifier les blocages (outils, processus, équipes). - *Simplification* : Réduire la complexité des pipelines. - *Formation* : Monter en compétences les équipes. - *Collaboration* : Impliquer les métiers dans la solution. Exemple : J’ai *redressé un projet* en 3 mois, évitant un préjudice de 500 000 €. Vous avez un *projet Data en difficulté* ? Parlons-en. #DataEngineering #RetourExpérience #Expertise #Tech #Luxe