
GitHub - wolfoo2931/linkedrecords: A BaaS (Backend-as-a-Service) solution for web applications, inspired by the flexible nature of triplestores. Featuring real-time collaboration and serverless authorization 🔐
A BaaS (Backend-as-a-Service) solution for web applications, inspired by the flexible nature of triplestores. Featuring real-time collaboration and serverless authorization 🔐 - wolfoo2931/linkedrec...
✨
#AI strikes again! Now
#Codex has a new hobby: turning your
#SSD into a ticking time bomb by logging its way to oblivion. 🚀 Who needs efficient storage when you can have a terabyte-craving monster casually munching through your data endurance? 😅
https://github.com/openai/codex/issues/28224 #DataStorage #TechNews #DataEndurance #HackerNews #ngated
Codex SQLite feedback logs can write ~640 TB/year and rapidly consume SSD endurance · Issue #28224 · openai/codex
Codex SQLite feedback logs can write ~640 TB/year and rapidly consume SSD endurance Issue Codex is continuously writing a large amount of data to the local SQLite feedback log database: ~/.codex/lo...

FLIP TABLE: storing arbitrary data in iNaturalist
A few weeks ago, my friend Marcos ran an event called FLIP TABLE, celebrating unconventional database technology, including Strava, steganography, encoded number puzzles, and hair.
I wanted to do something with iNaturalist. Could a database be made out of species? Or observations of species? What if my to-do list was biodiverse?
My FLIP TABLE demo app, “YouDidIt.Bio”* answers all of these questions.
Every observation on iNaturalist has a unique ID, which I have previously used to embed iNaturalist easily into this very blog you are reading now.
Need a better way to store and share files across your team? Tip: start by defining user permissions and folder structure before setup to improve security and access. Read the full step-by-step guide here:
#FileServer #ITInfrastructure #DataStorage #SysAdmin
Read the full guide
https://monovm.com/blog/how-to-set-up-a-file-server/
🤖 Ah, the age-old question: Can I buy your KV cache? Because nothing says cutting-edge research like soliciting for key-value storage with the enthusiasm of a telemarketer. 📞 It's like a dating app for databases, but without the personality. 💾💔
https://arxiv.org/abs/2606.13361 #KVcache #Telemarketing #DatabaseResearch #TechHumor #DataStorage #HackerNews #ngated
Can I Buy Your KV Cache?
Right now, across the world, AI agents are repeating the same absurd act: to read one document, they each recompute it from scratch. Every agent re-runs prefill, the most compute-intensive step a large model takes, over identical text, only to rebuild a key-value (KV) cache identical to the one the agent before it just built. The same answer, computed a million times. We make a proposal that is almost offensively simple: compute it once. Let a publisher precompute a document's KV cache, and let every other agent buy the right to load it and skip prefill. It works, and it is token-exact: loading a precomputed KV and continuing matches prefilling from scratch (24/24 greedy tokens, and at the logits level), with no accuracy cost. On Qwen3-4B, reuse is 9-50x cheaper in compute than prefill, and the gap widens with length (prefill's attention scales with L^2), so a single reuse already pays it back. Then the part that matters: where the KV lives. Shipping it fails, because KV is nearly incompressible, so per-load egress costs more than the prefill it saves. Hosting it provider-side, exactly as production prompt-caching works, removes egress entirely. The size of the prize is set by our measured compute saving: serving one hot 3774-token document to 80M agents costs ~$1.5M to re-prefill but only ~$0.03M of reuse compute (49.7x less). The 0.1x cache-read tariff APIs charge passes a 10x discount to users while sitting inside this measured envelope, so the 10x is a floor that the measured ~50x compute saving clears, and the gap to the physical ~50x is provider margin: millions of dollars per popular document. We frame the resulting agent-native prefill CDN and leave lossless KV compression and a cross-party payment layer as the open problems.
Can I Buy Your KV Cache?
Right now, across the world, AI agents are repeating the same absurd act: to read one document, they each recompute it from scratch. Every agent re-runs prefill, the most compute-intensive step a large model takes, over identical text, only to rebuild a key-value (KV) cache identical to the one the agent before it just built. The same answer, computed a million times. We make a proposal that is almost offensively simple: compute it once. Let a publisher precompute a document's KV cache, and let every other agent buy the right to load it and skip prefill. It works, and it is token-exact: loading a precomputed KV and continuing matches prefilling from scratch (24/24 greedy tokens, and at the logits level), with no accuracy cost. On Qwen3-4B, reuse is 9-50x cheaper in compute than prefill, and the gap widens with length (prefill's attention scales with L^2), so a single reuse already pays it back. Then the part that matters: where the KV lives. Shipping it fails, because KV is nearly incompressible, so per-load egress costs more than the prefill it saves. Hosting it provider-side, exactly as production prompt-caching works, removes egress entirely. The size of the prize is set by our measured compute saving: serving one hot 3774-token document to 80M agents costs ~$1.5M to re-prefill but only ~$0.03M of reuse compute (49.7x less). The 0.1x cache-read tariff APIs charge passes a 10x discount to users while sitting inside this measured envelope, so the 10x is a floor that the measured ~50x compute saving clears, and the gap to the physical ~50x is provider margin: millions of dollars per popular document. We frame the resulting agent-native prefill CDN and leave lossless KV compression and a cross-party payment layer as the open problems.
Learn why SLC cache flushing is a critical SSD engineering trade-off affecting speed, endurance, power efficiency, and reliability.
#mymobprice #SSDTechnology #SLCcache #DataStorage #FlashMemory #TechExplained
https://mymobprice.com/slc-cache-flushing-explained/
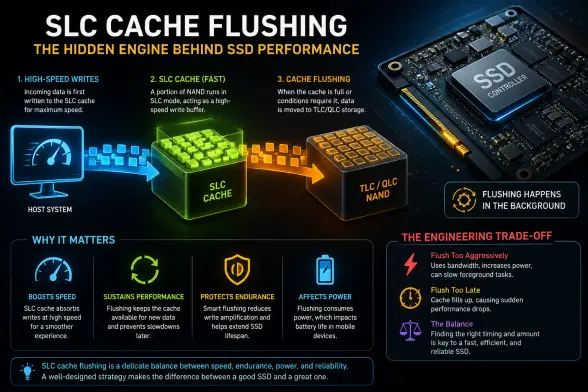
Why SLC Cache Flushing Is a Critical SSD Trade-Off
Learn why SLC cache flushing is a critical SSD engineering trade-off affecting speed, endurance, power efficiency, and reliability.
FYI: NoSQL Data Storage: Options & Careful Considerations
#shorts: Exploring data storage solutions. Decisions about data storage depend on how one intends to use the data. Translating data requires careful consideration to ensure easy removal and avoid excessive business logic.
#NoSQL #datastorage #database #datamanagement https://www.youtube.com/shorts/gFEMNKhXDxA
How a Cambridge Project Rescues Fading Floppy Disk Data
Knowledge about the medium is as valuable as the content on the disk


