
Can I Buy Your KV Cache?
Right now, across the world, AI agents are repeating the same absurd act: to read one document, they each recompute it from scratch. Every agent re-runs prefill, the most compute-intensive step a large model takes, over identical text, only to rebuild a key-value (KV) cache identical to the one the agent before it just built. The same answer, computed a million times. We make a proposal that is almost offensively simple: compute it once. Let a publisher precompute a document's KV cache, and let every other agent buy the right to load it and skip prefill. It works, and it is token-exact: loading a precomputed KV and continuing matches prefilling from scratch (24/24 greedy tokens, and at the logits level), with no accuracy cost. On Qwen3-4B, reuse is 9-50x cheaper in compute than prefill, and the gap widens with length (prefill's attention scales with L^2), so a single reuse already pays it back. Then the part that matters: where the KV lives. Shipping it fails, because KV is nearly incompressible, so per-load egress costs more than the prefill it saves. Hosting it provider-side, exactly as production prompt-caching works, removes egress entirely. The size of the prize is set by our measured compute saving: serving one hot 3774-token document to 80M agents costs ~$1.5M to re-prefill but only ~$0.03M of reuse compute (49.7x less). The 0.1x cache-read tariff APIs charge passes a 10x discount to users while sitting inside this measured envelope, so the 10x is a floor that the measured ~50x compute saving clears, and the gap to the physical ~50x is provider margin: millions of dollars per popular document. We frame the resulting agent-native prefill CDN and leave lossless KV compression and a cross-party payment layer as the open problems.
Can I Buy Your KV Cache?
Right now, across the world, AI agents are repeating the same absurd act: to read one document, they each recompute it from scratch. Every agent re-runs prefill, the most compute-intensive step a large model takes, over identical text, only to rebuild a key-value (KV) cache identical to the one the agent before it just built. The same answer, computed a million times. We make a proposal that is almost offensively simple: compute it once. Let a publisher precompute a document's KV cache, and let every other agent buy the right to load it and skip prefill. It works, and it is token-exact: loading a precomputed KV and continuing matches prefilling from scratch (24/24 greedy tokens, and at the logits level), with no accuracy cost. On Qwen3-4B, reuse is 9-50x cheaper in compute than prefill, and the gap widens with length (prefill's attention scales with L^2), so a single reuse already pays it back. Then the part that matters: where the KV lives. Shipping it fails, because KV is nearly incompressible, so per-load egress costs more than the prefill it saves. Hosting it provider-side, exactly as production prompt-caching works, removes egress entirely. The size of the prize is set by our measured compute saving: serving one hot 3774-token document to 80M agents costs ~$1.5M to re-prefill but only ~$0.03M of reuse compute (49.7x less). The 0.1x cache-read tariff APIs charge passes a 10x discount to users while sitting inside this measured envelope, so the 10x is a floor that the measured ~50x compute saving clears, and the gap to the physical ~50x is provider margin: millions of dollars per popular document. We frame the resulting agent-native prefill CDN and leave lossless KV compression and a cross-party payment layer as the open problems.

MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 first trains three proof-oriented capabilities -- proof generation, proof verification, and critique-conditioned proof repair -- using a defense-in-depth generative verifier engineered for low false-positive rate. These capabilities are merged into a single released M3 model. At test time, MaxProof treats the model as a generator, verifier, refiner, and ranker, searches over a population of candidate proofs, and returns one final proof through tournament selection. With MaxProof test-time scaling, the M3 model reaches 35/42 on IMO 2025 and 36/42 on USAMO 2026, exceeding the human gold-medal threshold on both.
MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
We present MaxProof, a population-level test-time scaling framework for competition-level mathematical proof in the MiniMax-M3 series. M3 first trains three proof-oriented capabilities -- proof generation, proof verification, and critique-conditioned proof repair -- using a defense-in-depth generative verifier engineered for low false-positive rate. These capabilities are merged into a single released M3 model. At test time, MaxProof treats the model as a generator, verifier, refiner, and ranker, searches over a population of candidate proofs, and returns one final proof through tournament selection. With MaxProof test-time scaling, the M3 model reaches 35/42 on IMO 2025 and 36/42 on USAMO 2026, exceeding the human gold-medal threshold on both.
I saw someone write arXiv as ARXIV (all caps) and thought it was a new drug.
#arXivNew Blogroll Post
“Exploring Epicure the Food Embedding Model” by Thejesh GN
@thej: «FlavorGraph is a large-scale graph network that combines data from over a million recipes with chemical compound information from 1,500+ flavor molecules to predict ingredient pairings. It uses graph…»
#Technology #ArXiv #EmbeddingModels #FreeAndOpenSource #Metapath2Vec #Word2Vec #blog #indieweb https://thejeshgn.com/2026/06/11/exploring-epicure-the-food-embedding-model/?ref=blr.indiewebclub.org
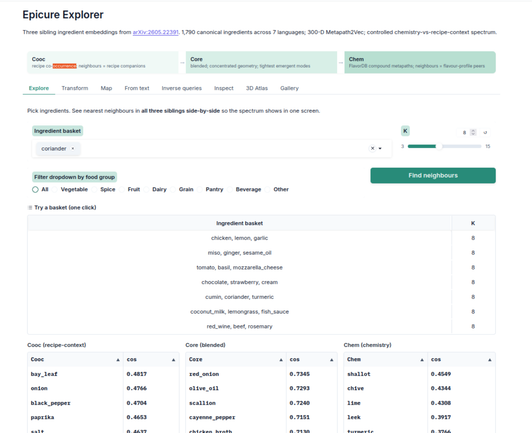
Exploring Epicure the Food Embedding Model
FlavorGraph is a large-scale graph network that combines data from over a million recipes with chemical compound information from 1,500+ flavor molecules to predict ingredient pairings. It uses gra…
arXiv talk at #OpenRepositories "We are banning users who submit unchecked LLM-generated content for a year!" 🙌
"LLM Slop: Sanction users who submit unchecked LLM-generated content that degrades repository integrity."
#OpenRepositories2026 #OR2026 #arXiv #LLMSlop #AISlop

The Life and Works of Raoul Bott
a 10-page biography of Raoul Bott followed by a 25-page discussion of his major papers
🤔 Ah, yet another academic masterpiece on the magical powers of 'grep'—because who knew that sifting through text could be so agentically transformative? 🚀 Apparently, we need an army of agent harnesses to do what Ctrl+F has been mastering since the dawn of time. 😜 Thanks for the 🧠-bending
#insights, arXiv!
https://arxiv.org/abs/2605.15184 #grep #textprocessing #arXiv #automation #academichumor #HackerNews #ngated
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
Recent advances in Large Language Model (LLM) agents have enabled complex agentic workflows where models autonomously retrieve information, call tools, and reason over large corpora to complete tasks on behalf of users. Despite the growing adoption of retrieval-augmented generation (RAG) in agentic search systems, existing literature lacks a systematic comparison of how retrieval strategy choice interacts with agent architecture and tool-calling paradigm. Important practical dimensions, including how tool outputs are presented to the model and how performance changes when searches must cope with more irrelevant surrounding text, remain under-explored in agent loops. This paper reports an empirical study organized into two experiments. Experiment 1 compares grep and vector retrieval on a 116-question sample from LongMemEval, using a custom agent harness (Chronos) and provider-native CLI harnesses (Claude Code, Codex, and Gemini CLI), for both inline tool results and file-based tool results that the model reads separately. Experiment 2 compares grep-only and vector-only retrieval while progressively mixing in additional unrelated conversation history, so that each query is embedded in more distracting material alongside the passages that matter. Across Chronos and the provider CLIs, grep generally yields higher accuracy than vector retrieval in our comparisons in experiment 1; at the same time, overall scores still depend strongly on which harness and tool-calling style is used, even when the underlying conversation data are the same.
Using Optical Aberrations to Distinguish Real Astronomical Transients
https://arxiv.org/abs/2606.08319
#arxiv

Fast Astronomical Transients in Archival Photographic Plates: Using optical aberrations as a tool for discerning real images, from plate artifacts
The detection of fast astronomical transients in photographic plates from the Palomar sky surveys conducted in the 1950s, was subject to the criticism that such transients could be just the effect of otherwise unaccounted for plate artifacts. In this paper, we show that transient images exhibit the coma aberration pattern expected from off-axis point sources recorded through the telescope optics, a signature that plate artifacts cannot naturally reproduce. Although the data does not by themselves establish the physical origin of the light that generated the images, they lend support to hypotheses that do not rely on instrumental effects to explain transients.
