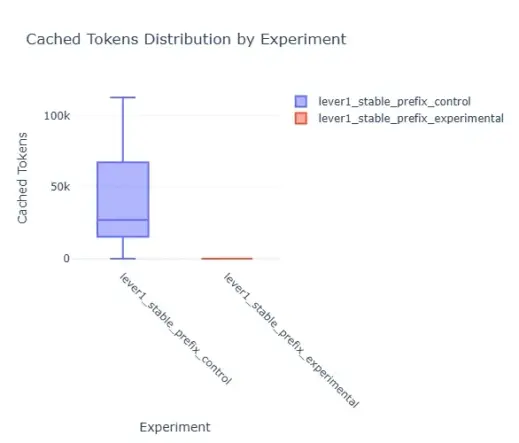
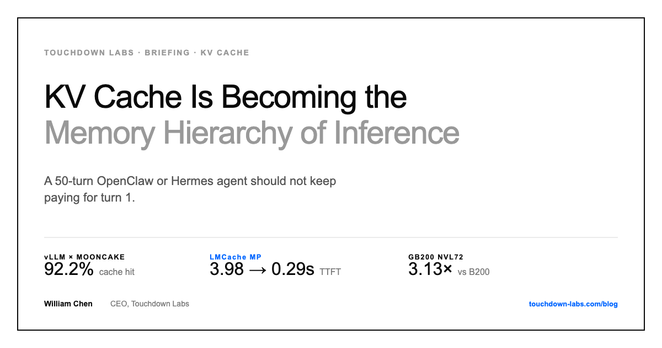
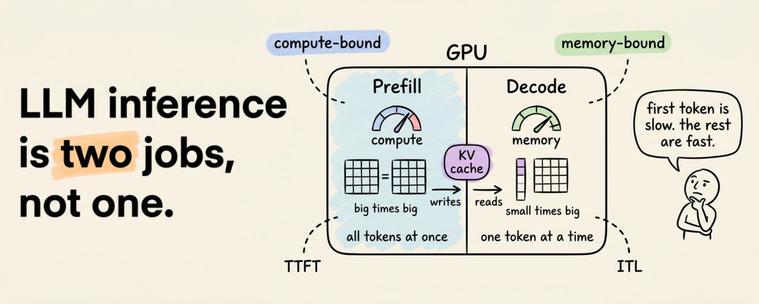
Prefix Persistence Unveiled in LLM KV Cache Dynamics
Learn how LLM KV cache prefixes remain unchanged, with masking used to manage them. This helps speed up AI responses.
#LLM, #KVcache, #AIefficiency, #PromptEngineering, #TechNews
https://newsletter.tf/llm-kv-cache-prefix-fixed-masking-efficiency/