DGX Spark на 256K контексте: тестирую конфигурации vLLM, реальные замеры и почему NVFP4 в mainline сломан
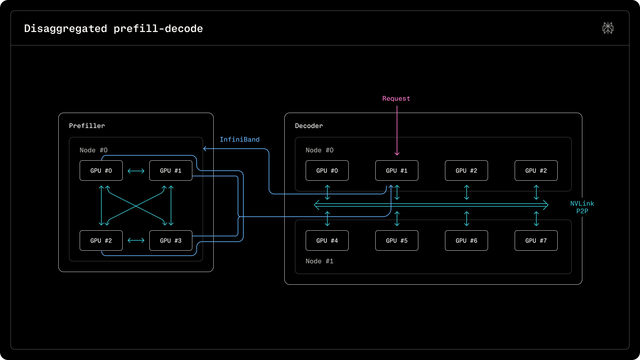
NVIDIA продаёт спарку с лозунгом «один петафлоп на FP4». Я купил коробку, поставил vLLM, запустил инференс и получил 40 токенов в секунду на 35B MoE‑модели. После маркетинговых слайдов цифра выглядит грустно. Объяснение простое. NVFP4 в основной ветке vLLM и FlashInfer физически сломан на SM_121 — варианте Blackwell, который установлен в GB10. Ядра собраны под compute_120f , а нативные NVFP4-инструкции есть только в compute_120a и compute_121a . На SM_121 распаковка квантованных весов идёт через программные битовые манипуляции в шейдере, без участия тензорных ядер. Сообщество вытащило стек руками: нашло обходные пути, собрало рабочие конфигурации. Я прогнал на своём Spark шесть разных конфигураций vLLM — от стокового BF16 до форка с DFlash speculative decoding — и замерил каждую одинаковым тестом. В этой статье разбираю, что в итоге работает и что выбирать под разные задачи.
https://habr.com/ru/articles/1033342/
#vllm #dgx_spark #gb10 #blackwell #nvfp4 #llm #инференс #локальный_ии