Ultimate ML interpretability bundle: Interpretable Machine Learning + Interpreting Machine Learning Models With SHAP by Christoph Molnar is the featured bundle of ebooks 📚 on Leanpub!

Линейная регрессия на стероидах: Double Machine Learning для устранения смещений в данных
Любой аналитик знает, что самым надёжным способом проверки гипотез являются рандомизированные контролируемые эксперименты (RCT), или, как их называют в народе — A/B-тесты. На практике часто возникают ситуации, когда провести A/B-тест невозможно — в основном это происходит по этическим или техническим причинам. Однако бывают кейсы, когда рандомизация невозможна потому, что treatment-ом является определённое действие пользователя. Например, treatment-ом может быть оформление платной подписки или отмена бронирования на сервисе. Давайте назовём такой вид воздействия добровольным. В русскоязычном пространстве, и в частности на Хабре, достаточно много статей, посвящённых таким методам Causal Inference, как DiD, PSM и Causal Impact. Тем не менее, к моему удивлению, практически нет статей, посвящённых методам на основе ортогонализации и regression adjustment, хотя, на мой взгляд, именно эти методы являются самыми удобными для оценки эффекта от добровольного treatment-а. Пришло время исправить это недоразумение и разобрать метод Double/Debiased Machine Learning (DML) и Partial Linear Regression для задач Causal Inference!
https://habr.com/ru/articles/1043704/
#causal_inference #machine_learning #abтестирование #причинноследственный_анализ #differenceindifference #psm #causalml #causalimpact #causal_effect #causality

Currently experimenting with exploration policies for deep RL on Super Mario Bros - Agent is able to beat all levels I threw at it - You can watch the AI learn live
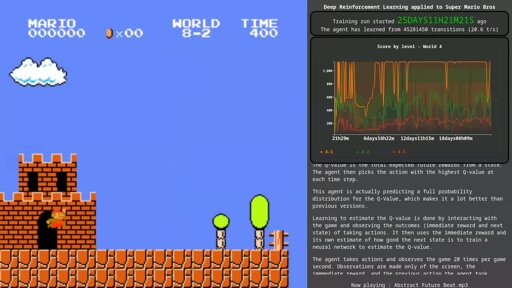
Currently experimenting with exploration policies for deep RL on Super Mario Bros - Agent is able to beat all levels I threw at it - You can watch the AI learn live - lemmy.pierre-couy.fr
publication croisée depuis : https://lemmy.pierre-couy.fr/post/2152233 [https://lemmy.pierre-couy.fr/post/2152233] > I’ve been playing with deep reinforcement learning for a while. I originally > started with a simple DQN, added all improvements from the Rainbow paper, and > finally changed C51 for a quantile regression (and plan to swap it for an > Implicit Quantile Network). > > After implementing C51 (which was my first time with distributional RL) I > started playing with policies that take advantage of the learned distributions : > By independently taking N samples from each action-value distribution, scoring > actions by averaging the samples, and picking the greedy action with respect to > these scores, I was able to make the agent learn faster than similar agents > using only NoisyNets or an epsilon-greedy policy (I’m still using NoisyNet, this > is done on top of it). In the limiting cases, N=1 is just Thompson Sampling > and N=+Infinity is just a plain greedy policy. > > Finding an optimal value for N proved to be a challenge, so I decided to pick > a random value for it at the start of each episode (N = 2**rng.uniform(8,12) > for a QR-DQN with 32 quantiles/action works well in my experiments), which led > to even better results. > > I later found out about > DLTV [https://proceedings.mlr.press/v97/mavrin19a/mavrin19a.pdf] which made the > agent discover new behaviors, but performed worse than previous experiments > overall. Inspired by it, I tried something I did not find in previous works and > got the best results out of all my previous experiments : > > At each time step, compute an exploration_score as the ratio of “intra-action > variance” over “inter-action variance” > (rendered latex equation [https://pierre-couy.dev/media/ext/drl_exploration_score_eqn.png]). > I then take N/exploration_score samples from each distribution, and pick an > action as described above. (more details at the end of this post) > > For anyone reading this, I have a few questions : > > 1. Are you aware of any previous work I missed that tries similar exploration > policies with distributional RL (interpolating between Thompson sampling and > the greedy policy) > 2. Most papers I found about learning from multiple exploration policies seem to > be in the context of multi-actor parallelization. Is there any novelty in > randomizing the policy parameters at the start of each episode, especially in > the single-actor case ? > 3. Is any part of what I’m doing worth the time it would take to quantitatively > evaluate it ? I’ve been doing it mainly for learning and fun and have only > qualitatively evaluated it so far. However, if there’s a chance I can > contribute to the field, I’ll gladly make some time to compare it to > published papers on ALE. > > ------------------------- > > #### A few more details > > I actually track a moving average and standard deviation of the exploration > score, which lets me shift/rescale its values to a target average and standard > deviation, and divide N by the shifted/rescaled value. I initially started with > a target average of 1 and standard deviation of 1 as well (which gave good > results), then tried randomizing these parameters at the start of each episode > as well. This led to a lot more diversity in the policies and even better > results. > > Since this worked so well, I additionally randomized the noise strength in the > NoisyNet layers. > > Overall, this made the agent a lot more robust to deviating from what it > considers to be the optimal trajectory, and allowed it to learn complex > behaviors previous iterations were never able to learn (e.g. taking a few steps > back to gain momentum, waiting for good cycles, or dodging hammer bros) > > ------------------------ > > #### Watch it learn > > For anyone interested, I made a > live stream of the training in progress [https://twitch.tv/pcouy_] with graphs > and some more details on the experiments I’m running. The current training run > was started ~2.5 days ago. The agent has finished and unlocked levels up to 5-1, and is currently learning 5-2. > > ----------------------- > > #### A lot more details > > ::: spoiler Long text hidden, click to expand > Available actions : The agent does not have access to the up and down > buttons, the available actions only use left, right, A and B. > > Adding the down button would double the total number of actions (because down > can be pressed on top of all available actions). > > Reward function : It mainly consists of > reward(t) = max(0, x(t) - previous_best_x) + a larger reward for beating a > stage. I had to tweak the scaling of both components. > > I initially had penalties for time and death, but one made the agent suicidal in > front of hard-to-overcome obstacles, while the other made it fear them too much > and hug the left side of the screen. Removing both proved to increase the > performance. > > One trick that seems to help with most ‘*-3’ levels (which have a lot of void > to fall into) was to hold the reward while the vertical velocity of Mario is > negative (meaning it is falling). Without this trick, the agent would sometimes > get stuck learning to jump the farthest it can into the void. > > Stage scheduling : Each episode is one attempt on one level. At the start of > each episode, a stage is randomly picked with probability proportional to > 1/(number of times the stage was beaten) among the unlocked stages. Each stage > is unlocked after the previous one has been beaten 30 times, with only 1-1 > unlocked at the start of the training. > > Available stages : The first iterations of the agent were unable to learn > maze castles (4-3, 7-3 and 8-4), so I removed them all. The reward function will > give rewards for the first path the agent tries, then the agent will be > teleported back by the game and no reward is received until it finds the right > path and gets past the point where the game teleported it back. I plan to test > newer (better) versions of the agent on these stages only and see if mazes can > be re-added to the pool. > > I’ve also removed underwater stages (2-2 and 7-2). The agent can learn them > fine, but the game dynamics are really different from all other stages and > they’re really boring to watch. Since I already removed a bunch of stages, I > figured I could remove these as well but I may re-add them with mazes because > beating every level is cooler than beating a cherry-picked selection. > > Since 8-4 is the only stage that requires going down a pipe, I considered it was > not worth it to add the down action and will likely never re-add it to the pool, > which would unfortunately be really anti-climactic… > > Replay buffer warm-up : After initially using the standard approach of > filling the buffer with transitions sampled from a random policy before training > the neural net, I came-up with a “soft warm-up” scheme in which the first > gradient updates happen after only 2000 transitions, but initially happen every > few thousand transitions and gradually become more frequent until the replay > buffer is full. Together with my custom exploration policy, this works very well > : the agent very quickly starts behaving similar to a “right + random button” > policy before learning to actually jump and run. > > Custom n-step bootstrapping : When I initially implemented n-step bootstrap > targets, I initially used n=3 from the Rainbow paper, noting the same > instabilities as the paper did for higher n values. I then found > the Retrace(\lambda) paper [https://arxiv.org/abs/1606.02647] which seems to > successfully address this by increasing n until the online network disagrees > with the action choice from a stored transition. This makes n larger where the > replay buffer data is on-policy, and smaller when it becomes off-policy. Since > my GPU is already maxed and the training is already slow (20.8t/s when real-time > is 20t/s) I could not afford the additional computations (building a training > sample (s(t), a(t), sum(r(t+0..n)), s(t+n)) needs up to n_max transitions to > go through the online network). > > I’m trying to achieve similar sample efficiency gains by using cheaper > alternatives as proxies for “how off-policy is a given transition” : I’m using > the number of times a transition has been sampled, with > n = int(max(n_min, n_max * k**times_sampled)) ; 0<k<1. The currently running > experiment uses n_max=14, n_min=1 and k=1/1.3. I’m pretty sure it helps > early in the training, and it does not collapse like a constant n=14 does > > Stream setup : As I said, this is something I do for my own fun, and I > really wanted to be able to see the agent learn in real time. The code runs a > separate process, to which frames from training episodes are sent in a queue. > The process then sends the frames as raw RGB24 to an local UDP socket, to which > GStreamer [https://gstreamer.freedesktop.org/] connects and encodes the stream. > With a simple MediaMTX [https://mediamtx.org/] configuration, I can manage the > Gstreamer process and have the stream available through WebRTC on my LAN. > > Then I figured someone else might have fun watching this, so I added a line to > my MediaMTX config to send the stream to twitch and youtube. The overlay is a > headless browser displaying custom HTML/JS (using d3.js for the graphs) piping > raw frames to ffmpeg [https://ffmpeg.org/]. GStreamer handles compositing the > two streams together into the side-by-side view. > > ::: >
Пока все смотрят на LLM: почему классический ML годами зарабатывает сотни миллионов?
Пока лента обсуждает LLM и агентов, а инвесторы спорят про окупаемость GenAI, «скучный» классический ML тихо зарабатывает реальные деньги. Я Senior Data Scientist в финтехе, выступаю с лекциями по карьере и ML в ИТМО и ВШЭ. Разберем в статье на цифрах пять компаний из четырех разных областей и почему классику рано списывать со счетов.
https://habr.com/ru/articles/1043056/
#data_science #машинное_обучение #machine_learning #data_analyst #junior #карьера_в_it #как_стать_data_scientist #классический_ML #собеседование #собеседование_data_scientist

Эволюция детекции дипфейков: от подсчета морганий до распознавания микроскопических изменений цвета кожи
— …для начала нужно понять главное. — Что главное? — Ложки не существует. В 2026 году этот диалог из фильма «Матрица» звучит уже не как философская метафора, а как обыденность в интернете. Все понимают, что видео теперь не является доказательством, голос больше не подтверждает личность, а в фотографиях от реальности нет и следа. Для обычного пользователя это означает потерю доверия к контенту, а для бизнеса — риск подделки личности, мошенничества и ошибочных решений. Как же так вышло, что нас повсюду окружают симулякры?
https://habr.com/ru/companies/ru_mts/articles/1040822/
#deepfake #AI #machine_learning #computer_vision #synthetic_media #FaceForensics++ #Intel_FakeCatcher #MNW_Benchmark #информационная_безопасность #генеративный_ИИ

[Перевод] Я залез в исходники Claude Code. Фичи, которых нет в документации
Оказывается, документация Claude Code рассказывает не всё. Стоило только лишь заглянуть в исходники. И вот что можно настроить, но чего нет в доке: — hooks, которые переписывают команды на лету; — автоодобрение safe-команд без лишних подтверждений; — постоянная память агентов между сессиями; — auto-mode, который понимает описание окружения на обычном английском; — самообучающиеся циклы памяти и «снов»; — скрытые поля skills, agents и permissions, которых нет в документации. И все это работает уже сейчас, а исходники Claude Code лежат у вас в node_modules . Мы собрали все в статью. Там больше конкретики, JSON-конфигов, shell-хуков и примеров, которые можно утащить себе почти без правок.
https://habr.com/ru/companies/spring_aio/articles/1041156/
#claudecode #claude #claude_code #claude_code_skills #claude_opus #ai #aiагенты #machinelearning #machine_learning #agent

Inside AI Meetup — как это было? Делимся записями докладов, фото и атмосферой
Привет! 20 мая прошел Inside AI Meetup от Wildberries & Russ — про практические кейсы внедрения ИИ: векторный поиск и модерация с 200+ моделями, AIOps для ML/GenAI-сервисов, RAG без галлюцинаций, запуск LLM-продуктов, генерация текстов из видео, поиск и рекомендации. В программе были кейсы от опыт Wildberries & Russ, MWS, Avito, VK, M2, МФТИ, Сбера, red_mad_robot и Альфа-Банка, а еще новые знакомства и полезный нетворкинг. В статье вы найдете видеозаписи с ивента и фото . Узнать больше
https://habr.com/ru/companies/wildberries/articles/1040624/
#ai #ии #искуственный_интеллект #ml #machine_learning #машинное_обучение #митап #ds #data_science #meetup

DRAйверы для GPU: как Kubernetes научился выделять устройства через стандартный API
Device Plugin в Kubernetes сводит GPU к счётчику на узле: планировщик видит только количество устройств, но не их профиль, объём памяти или режим шаринга. Для ML-задач это быстро становится ограничением. Обучению нужны выделенные карточки целиком, инференсу — управляемые доли, а CI хватит и четвертинки NVIDIA H100 на пять минут. Dynamic Resource Allocation полностью меняет модель управления устройствами. GPU становятся сущностью с инвентарём, атрибутами и правилами выбора. В статье я разбираю устройство DRA и показываю миграцию с device plugin на примере кластера из 8 узлов × 8 NVIDIA H100 без полного переписывания манифестов. А ещё объясняю, почему мы в Deckhouse пишем свой DRA-драйвер. Разобраться с DRA
https://habr.com/ru/companies/flant/articles/1038000/
#gpu #kubernetes #deckhouse_kubernetes_platform #ai #ml #dra #machine_learning

Кейс. Zero Bug Policy: как мы снизили бэклог багов в 4 раза за месяц
Баги — неизбежная часть разработки. В этой статье расскажу наш опыт: как мы внедрили Zero Bug Policy в нашем стартапе (B2B fintech) и за месяц сократили backlog с 77 до 18 багов. А главное — как это изменило культуру и отношения с клиентами. Прочитать про кейс
https://habr.com/ru/articles/1038644/
#zerobugpolicy #react #java #zero_bug_policy #QA #quality_assurance #качество #стабильность #backend #machine_learning

Build Your Own Coding Agent by J. Owen is on sale on Leanpub! Its suggested price is $34.99; get it for $15.99 with this coupon: https://leanpub.com/build-your-own-coding-agent/c/LeanpubWeeklySale20260519 #ai #python #software_engineering #machine_learning #computer_programming
