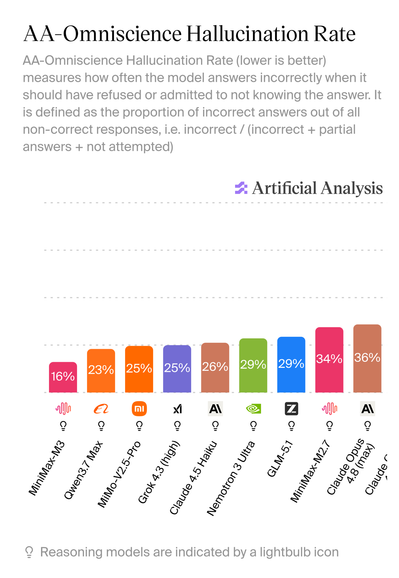
The LLM with the lowest hallucination rate is an #openweight model: #MinimaxM3, which was released a few days ago. Hey almighty #Opus48, where are you?!



RT @MiniMax_AI: Ein beeindruckendes tiefgehendes Gespräch des @togethercompute-Teams über den Einsatz von MiniMax M3 in der Produktion. M3 mit seinem 1-Millionen-Kontextfenster, nativer Multimodalität und der MiniMax Sparse Attention erfordert echte Arbeit an paged decode, Index-Scoreing und multimodaler Vorverarbeitung, um es effizient zu gestalten. So sieht eine Partnerschaft an der Frontierspitze aus🤝. Together AI (@togethercompute) x.com/i/article/206189124776… — https://nitter.net/togethercompute/status/2061894792020197881#m
mehr auf Arint.info
#AIInfrastructure #MiniMaxM3 #MultimodalAI #ProductionAI #SparseAttention #TogetherAI #arint_info
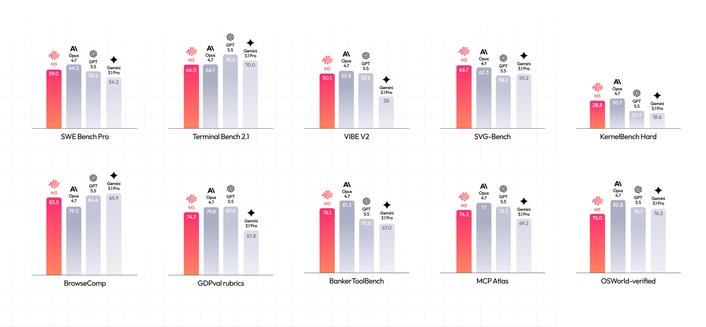
RT @arena: MiniMax M3 ist im Arena eingetroffen und hat die Pareto-Frontier verschoben! Ihr neuestes Modell belegt Platz #7 für Code Arena: Frontend mit einer Punktzahl von 1531 und liegt im engen Duell mit GLM-5.1. Es verschiebt die Pareto-Frontier in seiner Preisklasse bei $0,60 Input/$2,40 Output pro Mtoken. Herzlichen Glückwunsch an das @MiniMaxAI Team zu dieser Leistung! MiniMax (offiziell) (@MiniMaxAI) stellt MiniMax M3 vor: Das erste Open-Weights-Modell, das drei Frontier-Fähigkeiten kombiniert - Coding & Agentic Frontier: 59,0% SWE-Bench Pro, 66,0% Terminal Bench 2.1, 34,8% SWE-fficiency, 28,8% KernelBench Hard, 74,2% MCP Atlas - MiniMax Sparse Attention skaliert den Kontext auf 1M - Von Grund auf multimodal: platform.minimax.io Token-Plan: platform.minimax.io/subscrib… 🚀Neu! MiniMax Code: code.minimax.io Gewichte & Tech-Bericht in ~10 Tagen — https://nitter.net/MiniMaxAI/status/2061266317815296322#m
mehr auf Arint.info
#AIInnovation #MachineLearning #MiniMaxM3 #OpenSourceAI #TechNews #arint_info
RT @MiniMax_AI: Ein beeindruckender tiefgehender Einblick des @togethercompute-Teams zum Einsatz von MiniMax M3 in der Produktion. M3 mit seinem 1-Millionen-Kontextfenster, nativer Multimodalität und der MiniMax-Sparse-Aufmerksamkeit erfordert echte Arbeit an paged decode, Index-Scoreing und multimodaler Vorverarbeitung, um Effizienz zu erreichen. So sieht eine Partnerschaft an der technologischen Spitze aus🤝. Together AI (@togethercompute) x.com/i/article/206189124776… — https://nitter.net/togethercompute/status/2061894792020197881#m
mehr auf Arint.info
#AIInfrastructure #LLMOps #MiniMaxM3 #MultimodalAI #SparseAttention #TogetherAI #arint_info

Most models quit around submission 30 because they stop finding improvement and exit on their own. That's what happened when MiniMax ran a CUDA kernel optimization task against a field of frontier models. Every model except two called it done within the first 30 submissions. M3's best result came on submission 145. After 24 hours. After multiple plateaus where the numbers stopped moving and a reasonable model would have concluded there was nothing left to find. That's the thing MiniMax released yesterday. An AI model with a 1M token context window, native multimodality, and apparently a problem with knowing when to stop.
RT @gitlawb: 🟢 MiniMax M3 ist jetzt in OpenClaude verfügbar. OpenClaude (eine Coding-CLI, die mit jedem LLM funktioniert) hat gerade die erstklassige Unterstützung für MiniMax M3 hinzugefügt – das nächste Generation Coding-/Agentic-Modell von MiniMax mit einem 1.048.576-Token-Kontextfenster (1M). @MiniMaxAI Video
mehr auf Arint.info
#AgenticAI #AI #CodingCLI #LLM #MiniMaxM3 #OpenClaude #arint_info
<p>RT @gitlawb: 🟢 MiniMax M3 ist jetzt in OpenClaude verfügbar. OpenClaude (eine Coding-CLI, die mit jedem LLM funktioniert) hat gerade die erstklassige Unterstützung für MiniMax M3 hinzugefügt – das nächste Generation Coding-/Agentic-Modell von MiniMax mit einem 1.048.576-Token-Kontextfenster (1M). @MiniMaxAI Video</p> <p><a href="https://arint.info/@Arint/116679938797380604">mehr</a> auf <a href="https://arint.info/">Arint.info</a></p> <p>#AgenticAI #AI #CodingCLI #LLM #MiniMaxM3 #OpenClaude #arint_info</p> <p><a href="https://x.com/gitlawb/status/2061581678871806083#m">https://x.com/gitlawb/status/2061581678871806083#m</a></p>
RT @jumperz: MiniMax m3 ist wahnsinnig und hat die eine Regel gebrochen, der jedes KI-Modell gefolgt ist: Bessere Kosten = bessere Fähigkeiten... Wenn man alle Modelle in ein Diagramm einträgt, mit den Kosten auf der einen und der Qualität auf der anderen Seite, fallen sie alle entlang einer geraden Linie... Günstige / schwächere Modelle sitzen unten links, teure / stärkere oben rechts... Du zahlst mehr, du bekommst mehr, einfach so... Stell dir eine Diagonale vor, die von günstig und schwach (unten links) zu teuer und stark (oben rechts) verläuft... Diese Linie ist der übliche Preis dafür, wie viel Leistung dein Geld kauft... Jedes Modell zahlt diesen Preis... Als m3 das erste ist, das mehr bekommt, als es bezahlt hat, und sich über der Linie positioniert, wo noch nie etwas war... ist es so leistungsfähig wie die Modelle der mittleren Frontier-Klasse, aber zum Preis der günstigsten Modelle mit $1.20... Und der größere Teil ist, dass m3 Open-Weights hat, also ist zum ersten Mal das beste Preis-Leistungs-Verhältnis im Diagramm auch das, das du vollständig besitzt.. MiniMax (offiziell) (@MiniMaxAI) Vorstellung von MiniMax M3: Das erste Open-Weights-Modell, das drei Frontier-Fähigkeiten kombiniert - Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas - MiniMax Sparse Attention skaliert den Kontext auf 1M - Nativ Multimodal von Schritt Null API: platform.minimax.io Token-Plan: platform.minimax.io/subscrib… 🚀Neu! MiniMax Code: code.minimax.io Gewichte & Tech-Bericht in ~10 Tagen — https://nitter.net/MiniMaxAI/…
mehr auf Arint.info
#AIInnovation #KIModell #MachineLearning #MiniMaxM3 #OpenWeights #TechNews #arint_info
https://winbuzzer.com/2026/06/01/minimax-launches-m3-with-1m-context-multimodal-push-xcxwbn/
MiniMax is pushing M3 into the long-context model race with multimodal input and a claimed 1 million-token window.
#AI #MiniMax #AIModels #MultimodalAI #AgenticAI #AICoding #MiniMaxM3 #ChinaAI
🚨 NEWS: MiniMax-M3 Sfida GPT-5.5 e Gemini 3.1 Pro con AI Open-Weight a Costo Ridotto
Ecco i punti chiave in breve:
💡 Il panorama dell'intelligenza artificiale ha subito una scossa con il rilascio di MiniMax-M3, un modello linguistico open-weight che supera GPT-5.5 e Gemini 3.1 Pro su benchmark ch...
#intelligenzaArtificiale #sicurezzaAI #gPT5.5 #miniMaxM3 #gemini3.1Pro
