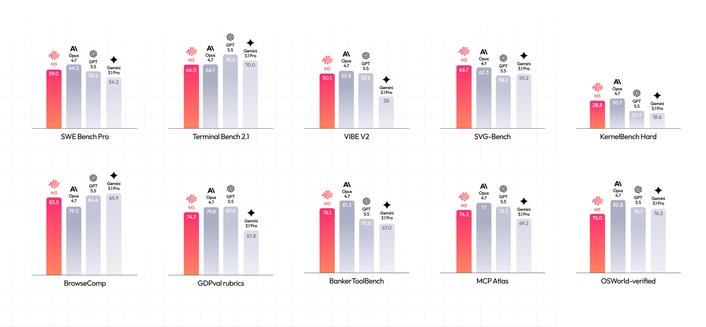
RT @jumperz: MiniMax m3 ist wahnsinnig und hat die eine Regel gebrochen, der jedes KI-Modell gefolgt ist: Bessere Kosten = bessere Fähigkeiten... Wenn man alle Modelle in ein Diagramm einträgt, mit den Kosten auf der einen und der Qualität auf der anderen Seite, fallen sie alle entlang einer geraden Linie... Günstige / schwächere Modelle sitzen unten links, teure / stärkere oben rechts... Du zahlst mehr, du bekommst mehr, einfach so... Stell dir eine Diagonale vor, die von günstig und schwach (unten links) zu teuer und stark (oben rechts) verläuft... Diese Linie ist der übliche Preis dafür, wie viel Leistung dein Geld kauft... Jedes Modell zahlt diesen Preis... Als m3 das erste ist, das mehr bekommt, als es bezahlt hat, und sich über der Linie positioniert, wo noch nie etwas war... ist es so leistungsfähig wie die Modelle der mittleren Frontier-Klasse, aber zum Preis der günstigsten Modelle mit $1.20... Und der größere Teil ist, dass m3 Open-Weights hat, also ist zum ersten Mal das beste Preis-Leistungs-Verhältnis im Diagramm auch das, das du vollständig besitzt.. MiniMax (offiziell) (@MiniMaxAI) Vorstellung von MiniMax M3: Das erste Open-Weights-Modell, das drei Frontier-Fähigkeiten kombiniert - Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas - MiniMax Sparse Attention skaliert den Kontext auf 1M - Nativ Multimodal von Schritt Null API: platform.minimax.io Token-Plan: platform.minimax.io/subscrib… 🚀Neu! MiniMax Code: code.minimax.io Gewichte & Tech-Bericht in ~10 Tagen — https://nitter.net/MiniMaxAI/…
mehr auf Arint.info
#AIInnovation #KIModell #MachineLearning #MiniMaxM3 #OpenWeights #TechNews #arint_info
https://x.com/jumperz/status/2061376241572151513#m