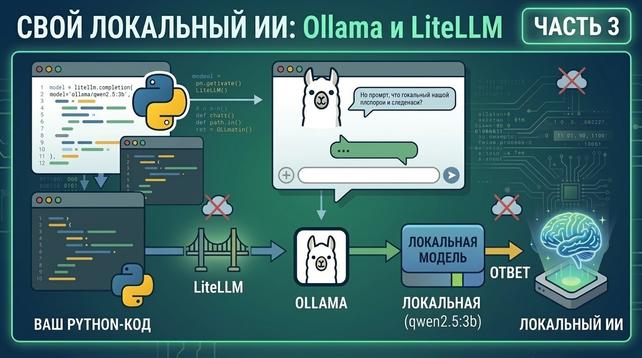
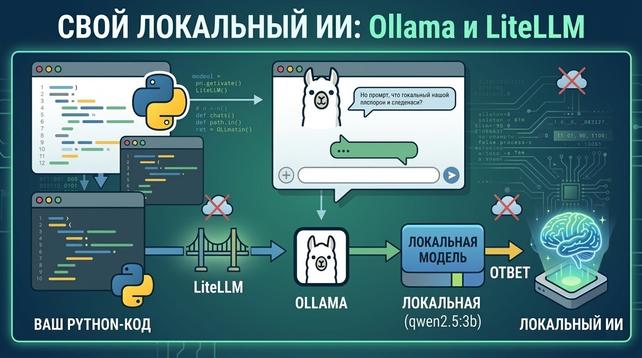
Richard Stallman, the founder of the free software movement, to talks about the relationship between AI and GNU. In the interview, Stallman reveals that one cannot define AI as OpenAI, stressing that the correct terms are LLM (Large Language Model).
🔹 The interview is in English with subtitles in English & Italian.
Richard Stallman, il fondatore del movimento del software libero, parla della correlazione tra AI e GNU. Nell’intervista, Stallman rivela che non si può definire AI quella di OpenAI, sottolineando che i termini corretti sono LLM (Large Language Model).
🔹 L’intervista è in Inglese con sottotitoli sia in Inglese che & Italiano.
Richard Stallman: "L’AI di OpenAI non è AI" – Il rapporto tra AI e GNU | AI Music Generation" / "OpenAI AI is not AI" – The relationship between AI and GNU | AI Music Generation —Manuel Cuda News >
https://youtu.be/V6c7GtVtiGc?si=neV06B6JXpqENrlE
#Richard_Stallman @rms #interview #video #LLM #AI #chatbots #Large_Language_Model #insight #GNU #Free_Software #English #Italiano