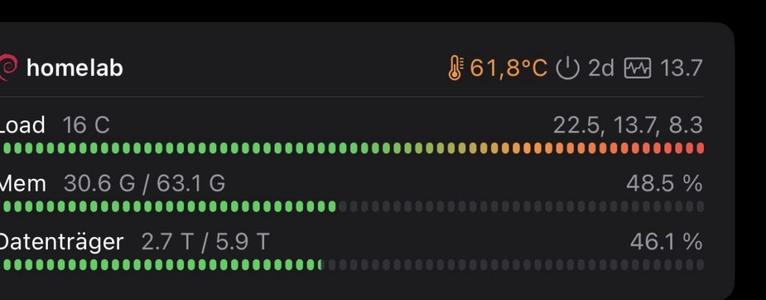
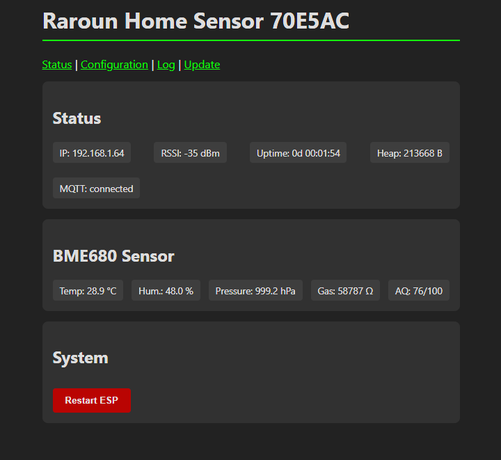
Dieses Projekt hat sich ein bisschen weiterentwickelt. Ich habe einen kleinen Sensorknoten gebaut, der Temperatur, Luftfeuchtigkeit und Luftqualität in der Wohnung erfasst. Es ist einfach ein ESP32-C3 Zero mit einem BME680-Sensor, der mit meinem lokalen MQTT-Broker spricht.
Das Gerät hostet seine eigene Weboberfläche für die Einrichtung – WLAN, MQTT-Topics und Schlafintervalle werden dort konfiguriert. Keine Cloud, kein Vendor-Lock-in, keine Dritt-Apps. Home Assistant zieht die Werte per MQTT und kümmert sich um Historie und Alarmierung.
Das Ganze kostet fast nichts. Wenn ein Board stirbt, flashe ich ein Ersatzgerät, gebe die gleichen Zugangsdaten ein, und es läuft sofort.
Akkulaufzeit bei 10-minütlicher Aktualisierung ca. 2-4 Monate.
Noice!
Firmware, die lokal auf dem Sensor läuft mit over the air Firmware Updates:
#selfhosted #decloud #datensouveränität #cloudfrei #righttorepair #vendorlockin #iot #esp32 #espc3 #mqtt #homelab #homeserver #diy #maker #3ddruck #asa #pcmodding #remoteaccess #lokaleinfrastruktur #opensourcehardware #3Ddruck #3ddrucker
RE: friendica.opensocial.space/obj…