Ultralytics (@ultralytics)
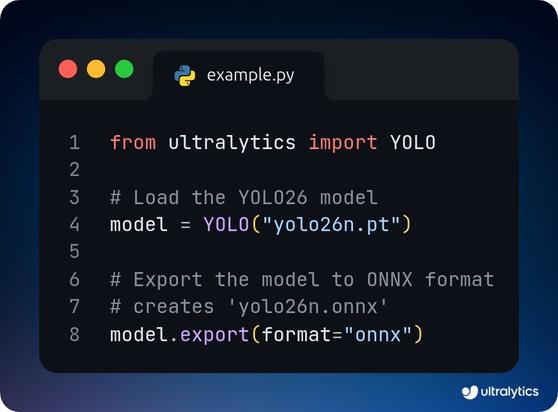
Ultralytics YOLO26 모델을 Python 코드로 로드한 뒤 TensorRT 엔진(.engine)으로 export하고 다시 불러오는 예시를 공유. 실전 배포에서 추론 최적화 파이프라인을 구성할 때 바로 참고할 수 있는 코드 스니펫.

Ultralytics (@ultralytics) on X
@nvidia Code 👇 """"""" from ultralytics import YOLO # Load the YOLO26 model model = YOLO("https://t.co/uEGGQDrLbd") # Export the model to TensorRT format # creates 'yolo26n.engine' model.export(format="engine") # Load the exported TensorRT model tensorrt_model =
 Qiita - 人気の記事
Qiita - 人気の記事


