Sudo su (@sudoingX)
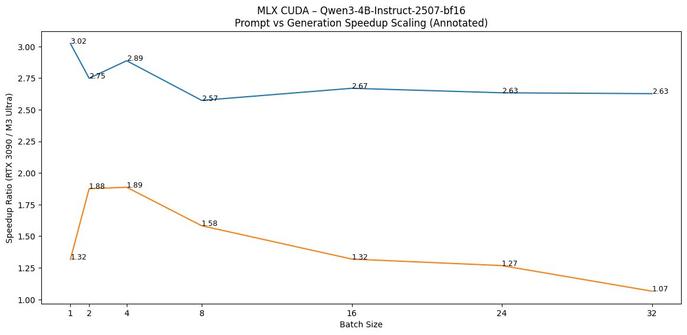
Hermes agent가 단순 과장이 아니라고 평가했습니다. 작성자는 단일 RTX 3090에서 Qwen 3.5 27B 베이스(Q4_K_M, 262K 컨텍스트, 초당 29-35토큰)를 완전 로컬로 구동해 '내 머신, 내 데이터' 환경을 구현했다고 보고하며, 에이전트에게 스스로 모델을 발견하도록 지시해 테스트한 경험을 공유했습니다.
Sudo su (@sudoingX) on X
okay the fuss around hermes agent is not just air. this thing has substance. installed it on a single RTX 3090 running Qwen 3.5 27B base (Q4_K_M, 262K context, 29-35 tok/s). fully local. my machine my data. first thing i did was tell it to discover itself. find its own model