What do we mean when we talk about AI and open knowledge?
Reflections on the future of sovereign, decentralised data management – Wikibase, Wikidata and beyond at the AI-Bridges Symposium
The AI-Bridges Symposium (28–29 May 2026) [1], hosted at Senate House, University of London, brought together diverse stakeholders from policy makers to academics, open knowledge advocates and funders, to discuss how AI is affecting the landscape of open knowledge. The underlying framework of the event was the recognition of the need for collective action when engaging with AI-related issues – a shorthand for an entangled bundle of tools and services, actually.
Over the course of the symposium, two main themes emerged: 1) The threat posed by commercial AI applications scraping the commons (open knowledge spaces) in an extractive manner; overloading the capacity of the socio-technical infrastructure without regard for the labour, codes of conduct and maintainer culture of commons communities, leaving behind frustration and distrust. 2) The flip side of this – the possibilities of using AI-supported workflows in actually lightening the load on maintainer communities; ensuring open knowledge continues to be shared freely and widely on the web through more accessible tooling for data integration, formatting and validation, with version controlled change histories.
Both themes open much room for discussion and potentially different routes for action. Mapping the landscape of relevant activities already happening in the common spaces was also part of the agenda. The various Wikimedia communities, both formal Foundation staff and affiliates as well as volunteers, are actively putting mechanisms in place to address threats and potential negative impacts (rate limits, targeted blocking, bans on AI-generated contributions, and more) and debating with mixed feelings the ifs and hows of AI-supported workflows [2]. At the same time there are also efforts across the research and public funding sector to deal with similar issues. Why not bring these efforts together?
This was one of the core propositions of the symposium: Why not consider how shared cultural heritage initiatives, such as Europeana or the European Culture Heritage Cloud among others, might help address the challenges also faced by the communities behind projects like Wikipedia, Wikidata, and Wiki Commons, and vice versa? And furthermore – the event asked us to think about the role of public funding bodies and government policies: Where can the positive energy and concern for democratic processes, knowledge sharing, and civic care converge rather than continue in isolated, siloed efforts with lower impact? [3] Participating as representative of both the EU-funded ECHOLOT project and the DFG-funded NFDI4Culture, I was at the right place for “staying with the trouble” [4] at the intersection of national and international research infrastructures and the digital commons.
Day 1: Training day
The first day was a hands-on training day within a smaller group of participants (~50) which offered the opportunity to level the ground with a common understanding of the data spaces of the Wikimedia ecosystem, namely Wikidata and Wikibase (and by extension their role in the AI development landscape). Solenne Lazare and Lydia Pintscher from Wikimedia Germany started off with an introduction to Wikidata, the large public knowledge base powering data in Wikipedia, while Leif Lobinsky ran the introduction session to Wikibase, the open source software suite behind Wikidata: What are the possibilities for sharing structured data within these systems, what example projects from diverse fields of knowledge already use them and what are current limitations and performance pain points?
As part of the hands-on testing, participants were invited to try modeling complex topics as data (e.g. news involving assumptions, uncertainties, etc.) within test instances of wikibase.cloud. The modeling experiment proved to be quite a challenge: while in Wikidata there are the existing items that can be used as guiding posts, in the case of Wikibase instances, starting from scratch offers flexibility at the cost of a high learning-curve. The way new users approach Wikibase as a data management tool might be to begin with federated properties and classes from Wikidata (if they’re already involved in that community), or to attempt to (re)build an ontology they might know from their domain (e.g. CIDOC-CRM in the culture heritage domain). The possibility of not having to start from scratch with basic properties and classes was discussed as a potential usability gain [5]. Clear patterns were emerging where additional support to users throughout different parts of the data management process would be beneficial.
In the afternoon, Philippe Saadé from Wikimedia Germany introduced the Wikidata Vector Database, what use cases it aims to support (e.g. Retrieval Augmented Generation, named entity recognition/ disambiguation, and classification) and where there is potential for more community engagement. Expanding the multilingual reach is one such goal, since currently vectors are calculated per language (so far: English, German, French and Arabic), but the search query entered in the LLM interface can be multilingual. A complementary development is the Wikidata MCP with a set of available tools. Using LLMs like Mistral (where connection to the internet can be closed down, so that the only source of truth becomes Wikidata) was demoed with promising results but is not entirely error-free yet, especially for SPARL query formulation. A brand new Wikibase MCP extends the connectivity to independent instances.
These recent developments engage seriously with the idea of AI-supported workflows that can increase the efficiency, accuracy and usability of the interactions between open knowledge communities and the data spaces offered by Wikidata or independent Wikibase instances. Gaps are admitted (e.g. in the case of language limits) and more community testing and contribution is actively encouraged – entirely in keeping with the spirit of free and open source software development. For example, fully fledged data reconciliation workflows that take advantage of the vector database are already being developed outside Wikimedia Germany, but in close discussion among the relevant communities [6]. This framing of ‘AI’ as software, as tools and services, which can actually be developed following FOSS principles, opened up the space to expand the discussion over the next days beyond the monolithic image of an external force, outside the control of the affected communities.
Community debates
In the last part of the day, a community gathering, led by Wikimedia Switzerland and Open Future, debated a new multi-partnership initiative for the Wikimedia movement that would be dedicated to addressing the AI-paradigm shift in a concerted and transparently-governed manner. The opening of the gathering was framed in a rather cautionary way: the urgent need to prevent extractive behaviours (both by bots and Big Tech commercial players), and implement stricter regulations and/or legal frameworks. At the same time, it is important to recognise how much of the existing tooling ecosystem is built around notions of usability dating from several decades ago and is still not open enough, or inviting enough, to diverse communities – humanities disciplines still struggle with the accurate modelling and translation of their qualitative work into data, while indigenous communities have established much more nuanced rights management pathways that fall outside the strict open/closed paradigm, to name just a few examples [7].
New paradigms in human-computer interaction, including natural language interfaces, as well as new legal frameworks that would effectively regulate access rights including bot/agent access, could actually be used to support and complement the interaction with the open knowledge ecosystem in ways that make the entire ecosystem more equitable – addressing problems that have been simmering below the surface far longer than the recent AI-hype cycles. The devil, as always, is in the details.
At this point in the day, I brought up the work of Audrey Tang from the Civic AI research project [8], which in a timely manner argues for the need to think about the original idea(l)s of FOSS – the open source freedoms – as applied to AI. If we frame AI as software, rather than as the threat of replacing human knowledge – a threat admittedly close to the heart of open knowledge communities – software can be governed through the principles of the FOSS freedoms. Moreover, these principles can encompass the right of refusal and rejection of extractive interactions, while adopting and adapting further beneficial workflow optimisations.
The notion of AI in the loop of communities, as elaborated by Tang, rather than the notion of the human in the loop of the AI, resonated strongly in the context of the Wikimedia movement and the link to Tang’s work was quickly circulated around the table. The gathering started with the proposition of taking an active stance as a global community of open knowledge advocates and concluded with the need to also put forward a positive vision and viable alternative, instead of merely (re)acting against Big Tech.
Reactionism can catalyse valuable critical points that need to be taken into account, but it cannot unite the movement when there is already a significant strain on the goodwill of volunteers dealing with overwhelming amounts of poor-quality, AI-generated data or harmful pull requests. A positive vision is necessary to recognise where the current ecosystem was found lacking even before the arrival of mainstream AI applications, and where it could be improved when it comes to dealing with sensitive topics, cultural nuances, and access rights. More relevant now than ever – where automated (mis)use can be scaled to unprecedented levels – advocates who have dealt with these topics in the past can bring in valuable insights to shaping the movement’s future.
Speakers at the AI-Bridges Symposium at Senate House in London. Image: Adrián Cuadrón, CC-BY.Day 2: The symposium
Day two featured extended discussions within an even wider group of participants, starting off with presentations from the AI-Bridges partners, leading to an expert panel and then a set of roundtable sessions. The panel discussion engaged a number of leaders from academic funding, policy making and Wikimedia communities, including Jimmy Wales, Denny Vrandečić and many more. The panel host, Shani Evenstein Sigalov, asked each panelist a particularly tough question which then required a succinct, but precise answer. The question addressed to me asked what is still missing in Wikibase and Wikidata infrastructures when it comes to meeting the needs of researchers and knowledge institutions. My answer, summarising the current status quo, what works and what doesn’t, is shared in full below (see Postscript).
In this context, ECHOLOT emerged as one of the much needed bridges across initiatives such as Europeana, the European Culture Heritage Cloud and the Wikimedia communities. As pointed out also by our panel host, all of these initiatives and communities deal with similar issues connected to aggregating open data on cultural heritage, protecting data from abuse (whether machine- or human-operated) and at the same time actively encouraging fair (re)use of that data. But the (re)use that could lead to scientific, societal and even economic value generation (for stakeholder communities), rather than value extraction, is hampered by the fact that the majority of the platforms are still not particularly easy to integrate with, to extract data from or to reuse that data, while respecting relevant copyrights. In short, there is a lot of open room for alignment and collaboration.
The panel also discussed the implications of missing the mark on using the productive capacity of the tools and services that AI methods can afford due to slow change cultures in some institutions. Nevertheless, the concerns coming from the GLAM community, the academic community, and also the volunteer citizen science knowledge commons, require paying attention to, as they are rarely born purely out of resistance to (fast) change. We can recognise, in the words of Denny Vrandečić, that LLMs trained on Wikipedia and Wikidata knowledge are objectively better for democratic societies compared to LLMs trained on data only from e.g. Twitter/X. Nevertheless, the care with which that knowledge has been put together originally has to be respected and has to be factored in the development of any new, value-generating tools.
One of the topics of the panel was also regulation: as a way to protect knowledge creation communities and regulate what value is generated and for whom. Paraphrasing the remarks of Aaron Halfaker (Principal Scientist, Microsoft): Big Tech could actually benefit from regulations. When the workers in these companies care about how these tools are being used, which is purportedly the case, regulation can help stimulate more fair business and market competition. If all companies have to compete on fair ground, theoretically they are more likely to develop tools wherein the benefits outweigh the harms.
I found this line of thinking productive, because it moved away from the ‘human-vs-machine’ discourse and brought back the companies into the picture; companies are legal entities that can in fact be subject to laws and regulation (though of course, how successfully regulation is implemented is another matter altogether). The ‘performer’ (e.g. contributors, users and developers of open knowledge platforms) vs the ‘tool maker’ (e.g. the company employees developing AI applications) paradigm, introduced in the book Behind Deep Blue [9] as an alternative to ‘human-vs-machine’, recognises people with one set of tools engaging with people with another set of tools [10]. If the human involvement is not abstracted away on one side of the equation, both sides can be subject to dedicated regulatory procedures. Crucially, regulation should not be restricted to licensing and/or IP attribution. As, Audrey Tang reminds us, FOSS is more than just licensing [11]. And caring about the rights of the ‘performers’ may not be enough, if the FOSS principles (and freedoms) are not fully applied to AI and its ‘tool makers’, including the right to refuse.
Jimmy Wales’s closing panel remarks also touched on the topic of trust, something Wikimedians and FOSS communities have managed remarkably well over time, and something that the AI-‘tool makers’ are currently less invested in building up, leading to the ongoing mixed-feelings or outright hostility amongst ‘performer’ communities.
Collaboration in practice, and not just in theory
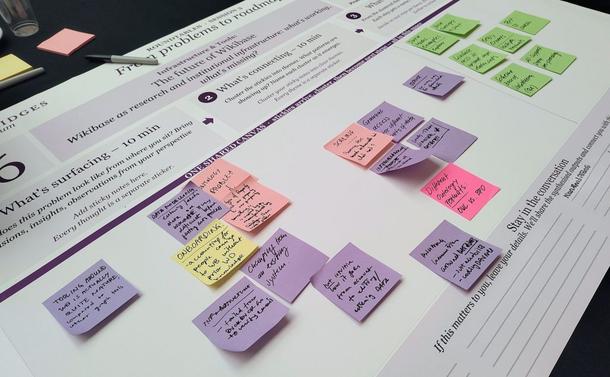
The panel ended on the positive note that everyone in the room seems interested and willing to collaborate, and of course everyone’s question was: how to make this happen instead of simply navel-gazing and wishful thinking? The roundtables in the afternoon provided an opportunity to think through some concrete actions. The setup meant that participants could take part in small group discussions across 18 different topics [12] via dedicated roundtables and take part in noting down:
- what current issues can be observed;
- what patterns emerge across connected issues;
- what are the next steps.
At the round table on the future of Wikibase, we noticed known issues related to data ingest, modelling, reconciliation and export workflows, still repeatedly being brought up and needing adequate measures to meet user needs, especially when scaling from manual curation to bulk operations. This is in fact the core motivation of applying AI methods to the tooling for managing structured data: the need to be able to more easily ingest the data, structure it, enrich, and then export to further platforms, supporting reuse.
Discussing the outcomes of the roundtable with colleagues from Wikimedia Germany, we came to the conclusion that we can’t build everything the community needs alone, but together there is a much stronger possibility. There are certain parts of the stack that make a lot of sense to be developed within the core product development at Wikimedia Germany, while other parts, such as micro-services that provide AI-supported automation, can be developed from external projects such as ECHOLOT and NFDI4Culture, among others.
We concluded the event with concrete commitments for joint meetings to plan the future development roadmap: interconnecting MediaWiki, Wikibase, new extension developments and the broader ecosystem of structured data, that can both be supported by AI-tooling and itself support the training of better and more equitable AI models.
Participant notes from the Roundtable discussion on the future of Wikibase. Image: Lozana Rossenova, CC-BYPostscript: Short position statement at the panel discussion
I will talk about Wikibase specifically, because Wikidata in general for all its scaling issues performs remarkably well on most levels that researchers and institutions need it to. As a tool offering openly licensed data and the possibility to freely link entities through their external identifiers, it offers the perfect hub for linked open data integration [13]. Wikibase, as its underlying open source software, appears to be the perfect starting point for researchers or cultural practitioners who want to model and make their original research data available, before it becomes a reference point for Wikidata – where we are not supposed to really directly add original research data. This very premise is compelling: I can have all my highly specialised or copyrighted data in a Wikibase and then seamlessly link it, or parts of it, via Wikidata by virtue of the fact that the two deploy the same software paradigm. In fact, it is the backbone of the idea of a federated ecosystem of instances around Wikidata shown in one particularly widely shared diagram [14].
And yet – there are issues. Wikibase is a complex Swiss-army-knife tool, it does a lot but it requires a high degree of technical skill and know-how to run and maintain in the long run – such skills are often not easy to come by in domain-specific research. It does not support easy compatibility with standard domain-specific schemas or ontologies. There is no simple upload schema button. There is no standard data validation in the sense required by typical FAIR research data projects. There are also no easy, straightforward export options to connect data from Wikibase even to Wikidata, or any other research data infrastructure. The latter is often a requirement for research – publish data to various national or international data aggregators. This is fine; Wikibase was never meant to solve for such cases. And yet, one can imagine the possibilities. Many of the limitations can be overcome with custom scripts, extensions and additional tooling, but maintaining, documenting and sharing this oftentimes lacks real reuse and reproducibility. This is more a fault of the scientific community, though, not the open knowledge community and is tied to the unsustainable funding cycles of research projects.
Efforts from the open knowledge community, such as wikibase.cloud – an important, major undertaking trying to resolve some of the learning-curve and maintenance limitations of the software suite – do not yet go far enough: images, for example. For many years now, I have advocated that the open knowledge community can learn a lot from research and GLAM communities when it comes to respectful and sensitive handling of copyrights, whether we are dealing with contemporary culture or indigenous rights [15]. Equally academia can learn a lot from the Wiki movement when it comes to long-term maintenance and keeping up infrastructure running. With the ECHOLOT project I’m now leading, we’re trying to offer a new bridge with concrete software development outcomes between EU research infrastructure and Wikimedia platforms and software. We are building better schema and copyrights handing models, easier export and integration possibilities with built-in, AI-supported processing workflows, wrapped around existing software. Not reinventing the wheel, but making it fit for different road conditions. We are open to collaboration and working together with anyone around the table today.
Acknowledgements
Thanks to Shani Evenstein Sigalov for the invitation and the opportunity to contribute to the Symposium and to the Wikimedia Germany team, and especially Leif Lobinsky for the productive discussions. Travel to the Symposium was supported by the ECHOLOT project, funded by the European Union under Grant Agreement n.101233096.
Notes
AI-Bridges is funded by the European Commission through a Marie Skłodowska-Curie Postdoctoral Research Fellowship. Led by Dr Shani Evenstein Sigalov and hosted at Digital Humanities Research Hub, School of Advanced Study, University of London, the project includes partnerships with the Wikimedia chapters in Germany, UK, Brazil, and Switzerland, and AI-experts Pleias.
Recent examples include dedicated sessions at the Wikimedia Hackathon 2026 in Milan, summarised with great nuance in a blog article by Hay Kranen, as well as upcoming sessions at Wikimania 2026 to be held in Paris in July.
The European Tech Sovereignty Package and EU Open Source Strategy were published on June 3rd, 2026, positioning open source and the digital commons as critical to Europe’s “resilience, competitiveness and strategic autonomy”. The strategy also admits that despite over 3 million open source contributors (according to the strategy fact sheet, but other sources point to even higher numbers), the European open source ecosystem faces “structural challenges” and lower impact due to value extraction outside Europe. The analysis from the Open Knowledge Foundation Network outlines further details.
See Donna J. Haraway (2016) Staying with the Trouble: Making Kin in the Chthulucene. Duke University Press.
Here, NFDI4Culture’s development of Wikibase4Research, which was mentioned as an example project application can be quite helpful, as it provides (among other resources), a GitLab repository with a sample ontology for the culture domain with scripts for transforming and loading the ontology in a fresh Wikibase instance.
At least one such example is the reconciliation of Basque entities currently underway at HiTZ-EHU as part of ECHOLOT, but there are likely many more.
See the published work of Anne Chen, Stacy Allison-Cassin and Kim Christen, among others.
The 2002 book by Feng-hsiung Hsu, the system architect of Deep Blue, which tells the story of how Deep Blue, “the ultimate chess machine,” beat Gary Kasparov in 1997.
This useful parallel to the discussions in Behind Deep Blue was initially drawn by Hay Kranen in his blog post on the Wikimania Hackathon.
See note #8.
Topics covered four broader areas such as AI Policy, Tools & Infrastructure, Trust & Education, Cultural Heritage & GLAMs. Full list is available here.
See Sohmen, L., Rossenova, L. and Blümel, I. (2026) ‘Wikidata 4 Open Culture: Lessons Learned from Hands-On Work with Cultural Heritage Data in the Expanded Wikibase Ecosystem’, Journal of Open Humanities Data, 12(1), p. 52. Available at: https://doi.org/10.5334/johd.440.
The image referred to is this one.
For example, see this blog post on provenance and museum data in the Wikiverse.