Google prezentuje Veo 3.1. Lepszy dźwięk i edycja w wideo generowanym przez AI
Google ogłosił wprowadzenie znaczących aktualizacji do swojego narzędzia do tworzenia wideo Flow, napędzanego przez nowy model sztucznej inteligencji Veo 3.1.
Najważniejsze zmiany to dodanie obsługi dźwięku do kluczowych funkcji oraz wprowadzenie zaawansowanych opcji edycji, dających użytkownikom większą kontrolę nad finalnym materiałem.
Sercem nowości jest model Veo 3.1, który stanowi rozwinięcie poprzedniej wersji. Według Google, nowa odsłona charakteryzuje się lepszym rozumieniem poleceń tekstowych (promptów), wyższą jakością audiowizualną oraz zwiększonym realizmem generowanych obrazów, w tym wierniejszym odwzorowaniem tekstur. To właśnie ten model napędza nowe możliwości, które trafiają do aplikacji Flow, gdzie od momentu jej premiery pięć miesięcy temu wygenerowano już ponad 275 milionów filmów.
Sztuczna inteligencja Veo 3 ożywi Twoje zdjęcia. Google Photos z dużą aktualizacją
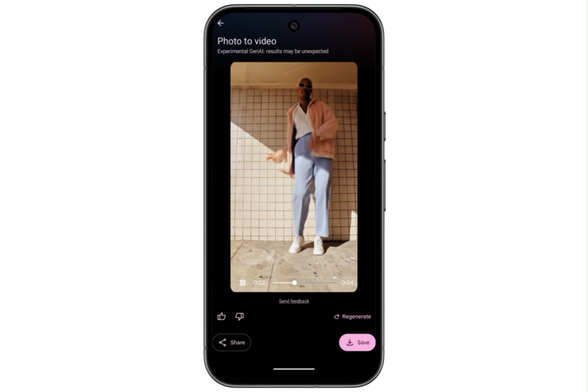
Po raz pierwszy Google wprowadza generowany przez AI dźwięk do istniejących już funkcji kreatywnych. Od teraz audio będzie tworzone w ramach opcji takich jak: „Składniki do wideo” (generowanie sceny na podstawie wielu obrazów referencyjnych), „Klatki do wideo” (tworzenie płynnego przejścia między obrazem początkowym i końcowym) oraz „Przedłuż” (wydłużanie istniejących klipów wideo). Ma to na celu tworzenie bardziej kompletnych i spójnych narracji wizualnych.
Największą nowością są jednak zaawansowane narzędzia edycyjne, które pozwolą na modyfikowanie już wygenerowanych scen. Pierwszą z nich jest funkcja „Wstaw”, umożliwiająca dodanie do klipu dowolnego obiektu – od realistycznych detali po fantastyczne postacie. Jak zapewnia Google, system potrafi przy tym uwzględnić złożone detale, takie jak cienie i oświetlenie sceny, aby dodany element wyglądał naturalnie. Wkrótce ma się również pojawić funkcja „Usuń”, która pozwoli na bezproblemowe wymazanie niechcianych obiektów, automatycznie rekonstruując tło.
Nowe możliwości napędzane przez model Veo 3.1 są już udostępniane użytkownikom narzędzia Flow. Jednocześnie technologia trafia do deweloperów poprzez API Gemini oraz do klientów korporacyjnych w ramach platformy Vertex AI. Zaktualizowane funkcje będą również dostępne w aplikacji Gemini.
Efekty? Zobaczcie sami na poniższym wideo udostępnionym przez Google DeepMind:
#AI #edycjaWideo #Flow #Gemini #generowanieWideo #Google #news #sztucznaInteligencja #textToVideo #Veo31 #wideoZAI