EyeingAI (@EyeingAI)
LTX-2가 로컬에서 실행되는 비디오 AI 제어 기술을 공개했습니다. 모션과 스타일을 세밀하게 제어하고 사용자 오디오를 추가할 수 있으며, 모델 자체를 수정할 수 있는 기능을 강조합니다. '가짜 오픈소스'와 결별을 선언하며 로컬 실행과 모델 편집을 통해 비디오 AI에 대한 통제권을 크게 확장한다고 주장합니다.
EyeingAI (@EyeingAI)
LTX-2가 로컬에서 실행되는 비디오 AI 제어 기술을 공개했습니다. 모션과 스타일을 세밀하게 제어하고 사용자 오디오를 추가할 수 있으며, 모델 자체를 수정할 수 있는 기능을 강조합니다. '가짜 오픈소스'와 결별을 선언하며 로컬 실행과 모델 편집을 통해 비디오 AI에 대한 통제권을 크게 확장한다고 주장합니다.
fly51fly (@fly51fly)
Infusion 논문은 영향력 함수(influence functions)를 활용해 학습 데이터를 편집함으로써 모델 행동을 조정하는 방법을 제안합니다. J. Rosser, R. Kirk, E. Grefenstette, J. Foerster(University of Oxford & UCL) 등이 제안한 'Infusion'은 특정 출력·행동 교정, 모델 디버깅 및 정렬에 적용 가능한 실무적 데이터 편집 절차를 보여줍니다.
Greg Schoeninger (@gregschoeninger)
통합된 생성/편집 기능에 대한 기대를 표명한 트윗으로, 기존에 LoRA를 학습시키고도 이미지 편집 기능을 바로 쓸 수 없던 불편이 해소되는 점을 긍정적으로 평가하고 있습니다.
fly51fly (@fly51fly)
논문 'Interpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits' 발표: 모델 행동을 해석하고 제어하기 위해 'constitutions' 기반의 원자적 개념 편집(atom-level concept edits) 기법을 제안합니다. 저자 N Kalibhat, Z Wang, P Bajpai, D Proud 등, Google DeepMind 소속이며 arXiv에 게재(링크 포함).
Brie Wensleydale (@SlipperyGem)
Qwen Edit에 대한 감상입니다. 작성자는 기술적으로 매우 인상적이지만 실용성에 의문을 제기하면서도, Qwen Edit이 지속적으로 유용한 결과를 내주는 도구임을 칭찬하고 있습니다.
Rome edits model weights to replace a fact the model knew with another
But, it sometimes ruined everything in the process
Not anymore, this was an implementation problem and
R-Rome solved it
☠️arrr- rome☠️
https://arxiv.org/abs/2403.07175
#nlproc #modelEditing #llm #llms #ml

Recent work using Rank-One Model Editing (ROME), a popular model editing method, has shown that there are certain facts that the algorithm is unable to edit without breaking the model. Such edits have previously been called disabling edits. These disabling edits cause immediate model collapse and limits the use of ROME for sequential editing. In this paper, we show that disabling edits are an artifact of irregularities in the implementation of ROME. With this paper, we provide a more stable implementation ROME, which we call r-ROME and show that model collapse is no longer observed when making large scale sequential edits with r-ROME, while further improving generalization and locality of model editing compared to the original implementation of ROME. We also provide a detailed mathematical explanation of the reason behind disabling edits.
How can we improve LM factuality and editability with nothing but the LM itself?
Introducing Deductive Closure Training (DCT):
1. generate statements and their implications
2. identify a logically consistent subset
3. distill this subset back to LM

You edit a model telling it Baiden is the U.S. president
Now you ask:
Who lives in the white house?
What do you think it answers? (hint: not Baiden)
@mega https://arxiv.org/abs/2307.12976
#nlproc #ModelEditing #machinelearning
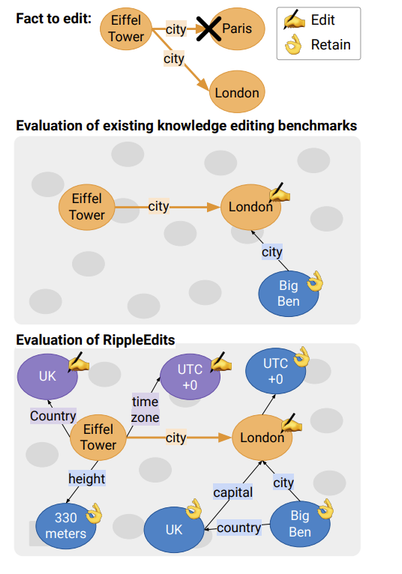

Modern language models capture a large body of factual knowledge. However, some facts can be incorrectly induced or become obsolete over time, resulting in factually incorrect generations. This has led to the development of various editing methods that allow updating facts encoded by the model. Evaluation of these methods has primarily focused on testing whether an individual fact has been successfully injected, and if similar predictions for other subjects have not changed. Here we argue that such evaluation is limited, since injecting one fact (e.g. ``Jack Depp is the son of Johnny Depp'') introduces a ``ripple effect'' in the form of additional facts that the model needs to update (e.g.``Jack Depp is the sibling of Lily-Rose Depp''). To address this issue, we propose a novel set of evaluation criteria that consider the implications of an edit on related facts. Using these criteria, we then construct RippleEdits, a diagnostic benchmark of 5K factual edits, capturing a variety of types of ripple effects. We evaluate prominent editing methods on RippleEdits, showing that current methods fail to introduce consistent changes in the model's knowledge. In addition, we find that a simple in-context editing baseline obtains the best scores on our benchmark, suggesting a promising research direction for model editing.
This entity wasn't in the pretraining😢
Don't cry, little ML researcher
Take new term definitions
Continue them with follow-up sentences
Distill your model (D-KL) to continue the same, without the definition
You know the new terms now
Go prompt them tiger🐯
Modern language models have the capacity to store and use immense amounts of knowledge about real-world entities, but it remains unclear how to update their implicit "knowledge bases.'' While prior methods for updating knowledge in LMs successfully inject facts, updated LMs then fail to make inferences based on these injected facts. In this work, we demonstrate that a context distillation-based approach can both impart knowledge about entities and propagate that knowledge to enable broader inferences. Our approach consists of two stages: transfer set generation and distillation on the transfer set. We first generate a transfer set by simply prompting a language model to generate a continuation from the entity definition. Then, we update the model parameters so that the distribution of the LM (the student) matches the distribution of the LM conditioned on the definition (the teacher) on the transfer set. Our experiments demonstrate that this approach is more effective in propagating knowledge updates compared to fine-tuning and other gradient-based knowledge-editing methods without compromising performance in other contexts, even when injecting the definitions of up to 150 entities at once.





