🎉 Milestone Unlocked: Finished the Data Engineering Zoomcamp!
In 10 weeks, I moved from scripting to architecting systems. We built real production-grade infrastructure using Spark, Kafka, Airflow, and Kestra—not just hobby projects.
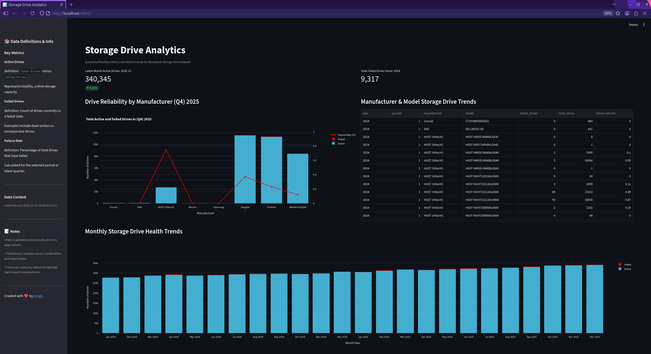
Capstone: A Storage Hard Drive Dashboard using real failure data from Backblaze
Stack: Terraform + Docker infra, Airflow orchestration, dbt modeling, Streamlit viz.
Key Lessons:
✅️ "It works on my laptop" isn't a strategy.
✅ Need IaC, partitioning, clustering, and strict error handling.
✅ dbt ensures reproducible, tested models.
✅ Infra is invisible work—if it breaks, your code fails.
Take the leap! It’s challenging but by week 10, pieces click into place. Seeing my pipeline run autonomously felt like crossing the finish line. 🏁
Thanks Data Talks Club team! On to the next challenge!
My project: https://github.com/ammartin8/hard_drive_analytics_dashboard
#mastodon #fediverse #data #spark #dataengineering #ai #technology #datatools #datapipelines #fedihire #thursday #sql #observability #etl #python #github