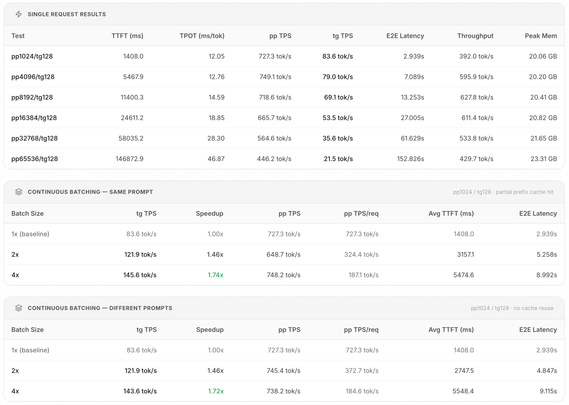
Stürzt bei noch jemandem in #lmstudio das #model ohne weitere Info ab, wenn er eine Datei in den Chat gibt und Vision verwendet? Bei mir jedes mal. An #qwen oder der Systemlast kann es nicht liegen.
Hab schon mit #ollama probiert. Hat zwar 5 Minuten gebraucht, um die Katze zu beschreiben, weil er noch Thinking gemacht hat, aber das Ergebnis war zufriedenstellend und ich hatte keinen Crash.
"The model has crashed without additional information. (Exit code: null)"