LM Studio 新增遠端存取功能 iPhone 連接家中 PC 運行本地 AI
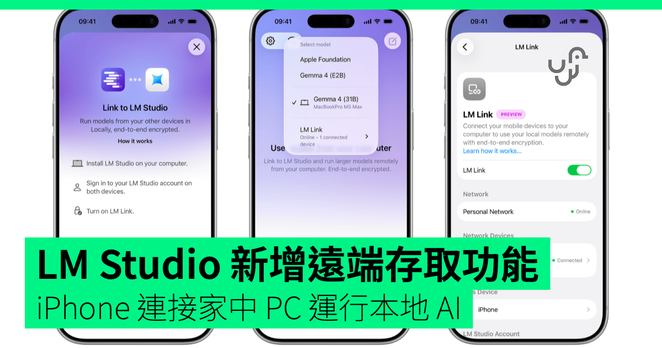
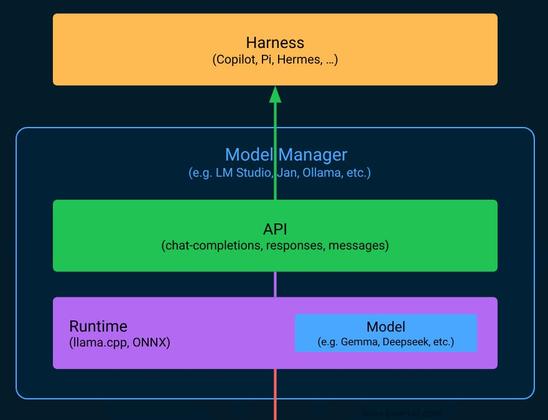
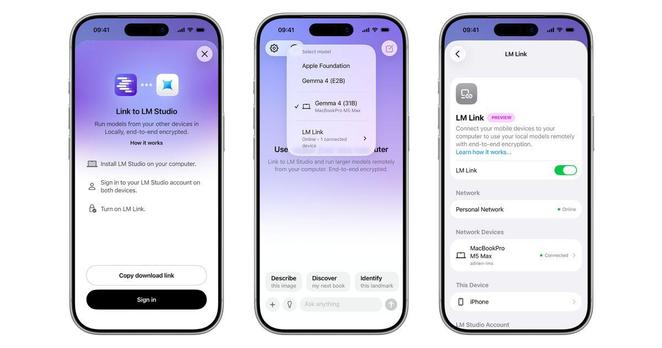
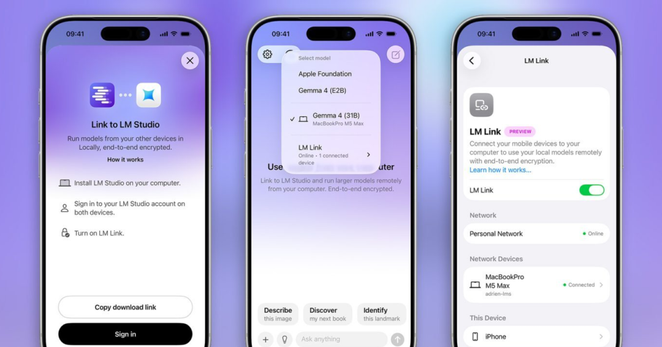
LM Studio 正式推出 LM Link iPhone 支援。用戶只需在手機安裝 Locally 應用程式 […]
#人工智能 #iOS App #iPad App #iPhone app
https://unwire.hk/2026/06/06/lm-studio-lm-link-iphone-remote-ai/ai/?utm_source=rss&utm_medium=rss&utm_campaign=lm-studio-lm-link-iphone-remote-ai
LM Studio 正式推出 LM Link iPhone 支援。用戶只需在手機安裝 Locally 應用程式 […]
#人工智能 #iOS App #iPad App #iPhone app
https://unwire.hk/2026/06/06/lm-studio-lm-link-iphone-remote-ai/ai/?utm_source=rss&utm_medium=rss&utm_campaign=lm-studio-lm-link-iphone-remote-ai