Бенчмарки и метрики сравнения с продуктами-конкурентами как инструменты повышения качества мобильного приложения
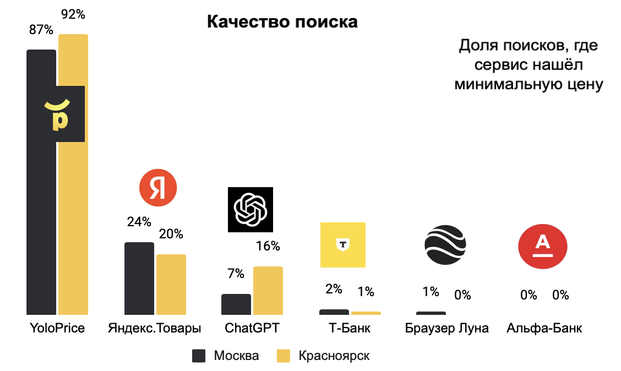
Привет, Хабр. Я всё тот же разработчик YoloPrice, приложения для поиска и сравнения цен по маркетплейсам, интернет-магазинам и классифайдам. В прошлый раз я рассказал, как я привлек бесплатно несколько тысяч новых пользователей. Но просто привлечь пользователей это одно, а вот сделать так, чтобы они регулярно начали пользоваться приложением и рекомендовали его другим - это задача со звездочкой. Расскажу в этой статье, как я ее решал. Для решения этой задачи продуктовые команды используют термин Product Market Fit (PMF) - это состояние, когда продукт удовлетворяет реальную потребность (ее часто называют “боль”), вызывая активный спрос у целевой аудитории. При этом, пользователи не просто пробуют продукт, а регулярно используют, платят за него и рекомендуют другим, демонстрируя его ценность. Для пользователей сервисов сравнения цен PMF = Сервис экономит время и деньги. Без этого пользователи уйдут к конкурентам или в обычные поисковые системы. Для своего приложения, анализируя поведение пользователей, я заметил, что первым делом меня проверяют на том, что недавно покупали, и если я теряю товары с минимальной ценой, то это приводит к недоверию и отказу от дальнейшего использования. Таким образом, в моем приложении основной блокер начала использования сервиса и один из ключевых для PMF - сервис не находит минимальную цену/предложение, о котором явно пользователь знает и использует для первичной проверки YoloPrice. Самый очевидный способ устранения данного блокера - брать запрос пользователя и проверять, потеряли ли мы минимальную цену или нет. Но этого мало, нужно понимать насколько твой продукт по ключевым метриками для PMF лучше/хуже альтернативных способов удовлетворения потребности Пользователей (читай - конкурентов) и регулярно отслеживать рэнкинг по этим метрикам.
https://habr.com/ru/articles/926910/
#бенчмаркинг #мобильная_разработка #product_market_fit #мобильные_приложения #сравнение_цен #поиск_товаров #исследование_рынка #принятие_решений