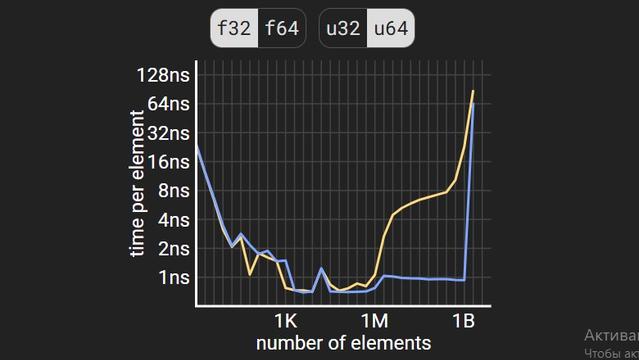
[Перевод] На сколько же медленнее произвольный доступ на самом деле?
Как вы, наверно, знаете, из-за наличия в компьютере различных кэшей (L1, L2, L3...) и того, что операции с памятью выполняются с линиями кэша размером примерно 64 байт каждая, для обеспечения максимальной производительности мы должны писать программы, обеспечивающие локальность . (Разумеется, диск здесь не показан) Но насколько хорошо вы это осознаёте? Допустим, у нас есть массив чисел с плавающей запятой и массив индексов первого массива. Есть программа, складывающая числа из первого массива в порядке, определяемом вторым массивом. То есть в этом примере мы будем складывать ε + α + δ + ζ + β + γ в таком порядке: Давайте рассмотрим всего два случая: индексы идут в порядке от первого до последнего или в произвольном порядке . До того, как я начал писать этот пост, я не мог ответить ни на один из следующих вопросов: 1. Насколько большим должен быть массив, чтобы разница производительности вычисления в двух порядках стала заметной? 2. Сколько в среднем тратится на каждый элемент в порядке от первого до последнего? 3. Насколько медленнее произвольный порядок последовательного в случае массивов, умещающихся в RAM? 4. Насколько медленнее произвольный порядок последовательного в случае массивов, не умещающихся в RAM? 5. Достаточно ли стандартного тасования Фишера-Йейтса для массивов перемешанных индексов для получения произвольного порядка? 6. Насколько медленнее порядок от первого до последнего в случае массивов, не умещающихся в RAM, при использовании файлов с отображением в память? 7. Максимально ли быстры файлы с отображением в память? Если вы уже знаете ответы на эти вопросы, то это замечательно! Если же нет, то делайте ваши предположения и проверьте их, прочитав пост.
https://habr.com/ru/articles/922800/
#кэш #memory_mapped_files #бенчмарки