Choose One and Boost Please
Dilly-Dally
Lollygag
Poll ended at .

Choose One and Boost Please
DRAGONFLIGHT (1978)
Acrylic on Masonite - 20" X 30"
For the first book in Anne McCaffrey's now legendary Dragonriders of Pern series, I wanted to create a literal visualization of the title. I selected an aerial point-of-view and tilted the horizon to simulate the dizzying sensation of flight. 1/4
#sciencefiction #scifi #scifiart #sff #illustration #annemccaffrey #pern
#dragon

It’s not too late to start masking.
You don’t have to do it alone. You won’t be the lone masker.
There’s an engaged Covid cautious and disability community who will help you.
There’s local mask blocs who provide respirators to those who can’t afford them.
Covid is still here, and masks work!
Wow. This is as close to perfection as I've seen when it comes to accurately representing expressive characters using nothing but #LEGO. The faces on the bus and on Totoro are spot on using nothing but bricks.
Amazing work.

Stay informed about reported ICE sightings, within a 5 mile radius of your current location, in real-time while maintaining your privacy. ICEBlock is a community-driven app that allows you to share and discover location-based reports without revealing any personal data. KEY FEATURES: • Anonymi…

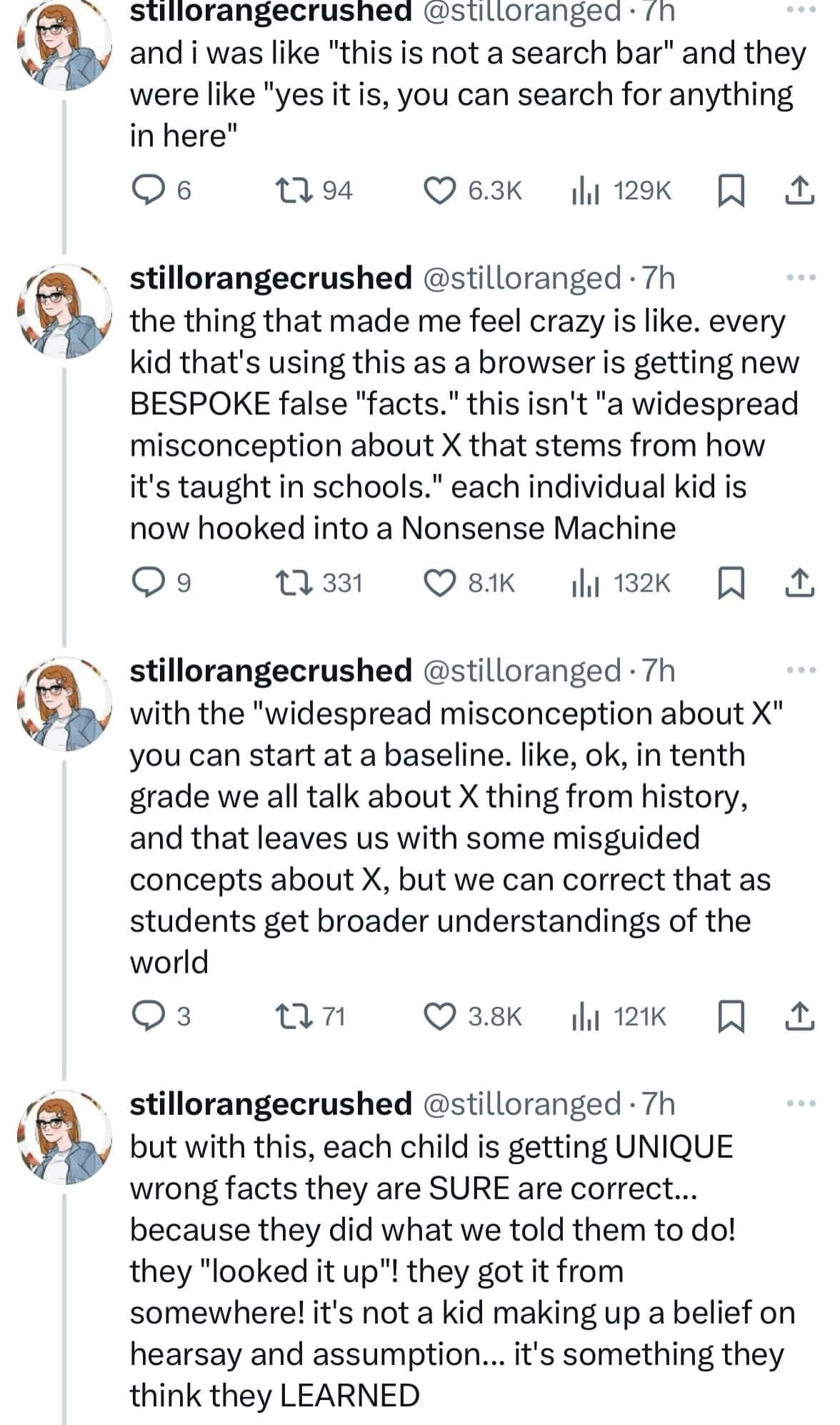
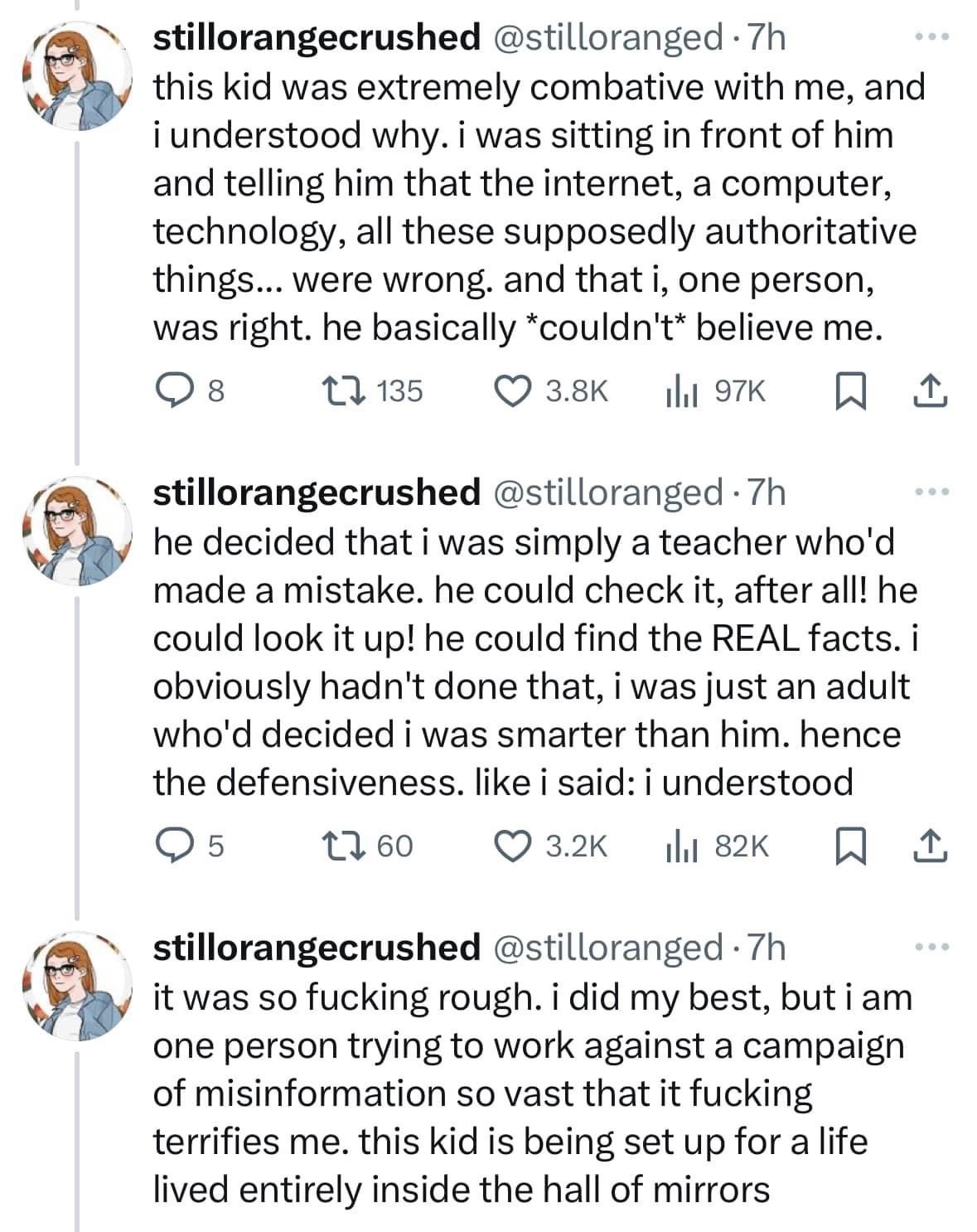
@b_rain This also ties into how the way we design things influences how people percieve them.
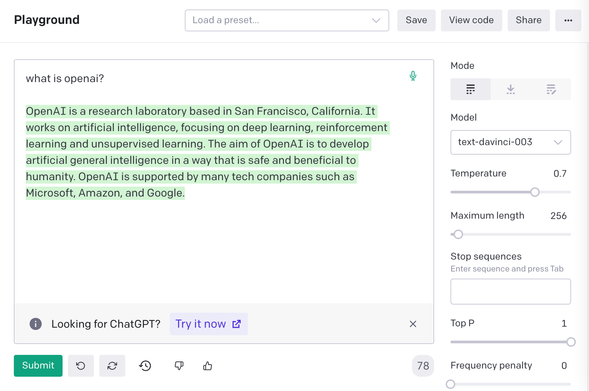
Before ChatGPT, there was "OpenAI Playground," a paragraph-sized box where you would type words, and the GPT-2 model would respond or *continue* the prompt, highlighted in green.
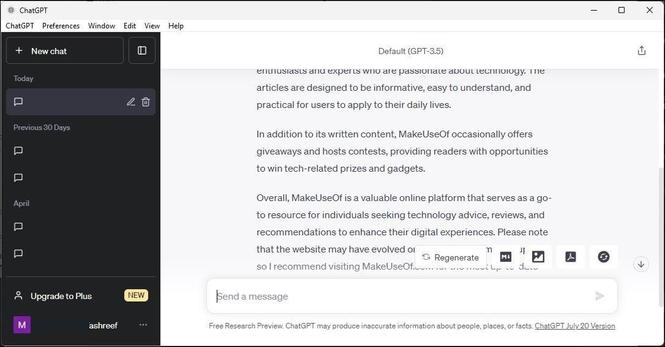
Then ChatGPT came along, but it was formatted as a chat. Less an authoritative source, more a conversational tool.
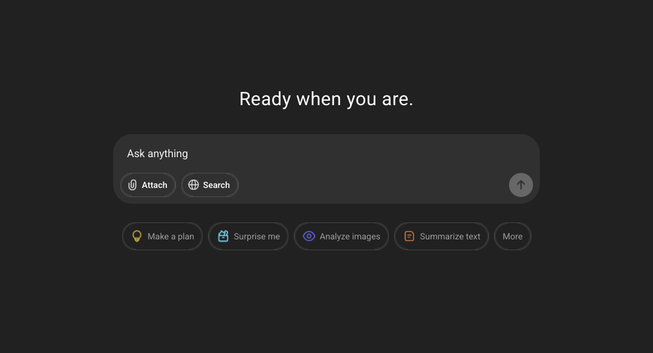
Now the ChatGPT home page is formatted like a search engine. A tagline, search bar, and suggested prompts.
@jollysea Technically the models can vary a bit in how they handle that (e.g. they could be using an XML format with <user> and <llm> for example) but yeah, that's the structure essentially all conversational LLMs have to follow.
In the end, LLMs are just word prediction machines. They predict the most likely next word based on the prior context, and that's it. If nothing delineated between the original prompt and the LLM's response, it would naturally just continue the prompt.
@jollysea That was actually one of the most fun parts about the original interface. If you wanted it to continue some code, just paste in your code and it'll add on to it. Have a random idea for a poem? Write the first line, and it'll write a poem that continues from that starting line in a more cohesive manner.
Now any time you ask an LLM to do something, it won't just do the thing you wanted, it'll throw in a few paragraphs of extra text/pleasantries/re-iteration you didn't ask for.
@LordCaramac I'd assume that has something to do with how GPT2 was a lot more loosely fine-tuned than GPT3 and subsequent models.
GPT2 was more of an attempt at simply mimicking text, rather than mimicking text *in an explicitly conversational, upbeat, helpful tone designed to produce mass-market acceptable language*
Like how GPT2 would usually just do the thing you asked for, whereas GPT3 and others now all start with "Certainly! Here's a..." or something similar.
@jollysea @boltx @b_rain yeah. OAI and friends are desperately trying to add as much abstraction & as much features on top of LLMs to hide the fact they're just the predictive text on your phone but overgrown.
its just that the training data always had a specific 'token' to delineate user input and expected output so the LLM behaves like a chat bot
Teach kids (and adults) to check sources. Where does chatGPT get this info? Learning to check sources is a useful skill in manu situations. Note that Wikipedia lists its sources. ChatGPT makes them up.
Also teach them that ChatGPT is the ultimate bullshitter. It's designed to always produce an answer, regardless of whether it's true or false. It has no concept of truth. It just makes stuff up based on the content it's trained on, which means it's sometimes correct, but mostly by accident. It can also be very wrong.
No matter what you use it for, always, always double check the output of these LLMs. Because it's just as likely to be bullshit as true.
@mcv The biggest problem is, in my view: the answers are most of the time at least working. If you ask for something that is reasonably well trained, it will get you valid answers.
But how do you know when it’s wrong? You don’t.
Checking sources is a good sentiment, but given those things throw in vast texts, you cannot really check it; it defeats the purpose of those AIs.
Now, then don’t use ChatGPT!
But there’s no escape, you will just get another AI, from another vendor.
We’re toast.
@b_rain I've had to explain that LLMs are nothing at all like search engines to friends who are highly educated and, overall, likely smarter and more capable of complex thought than myself.
They're just not computer science educated, and understand computers as good at numbers and large database retrievals.
Which is the exact opposite of #LLMs.
Society isn't ready for them at all.
@larsmb @b_rain And indeed lots of supposedly "highly educated" people in lots of specialized fields have this very basic lack of intelligence.
For example there are tons of doctors who take claims by drug companies at face value rather than applying a critical lens, looking for genuinely independent studies, or applying their own understanding (that they theoretically needed to graduate, but probably never had) of the relevant mechanisms of action.
@dalias @b_rain No. This is insulting. I don't take kindly to insults to my friends, so kindly: don't.
They're not experts in tech. They're being willfully misled about the capabilities and functions.
They all understood it when explained, but the systems are not always explained, because then they couldn't be sold.
The term for "one can't spend time to understand everything and must rely on and trust others at some point" is not "unintelligent" but "human".
@larsmb @b_rain OK I'll try to refrain from doing that.
What I'm trying to say is that the answer to "can't understand everything" is not "trust whoever has a loud marketing department" but "assume hype and extraordinary claims false by default especially when they're coming from corporate sources in the same industry that's making the hyped products" and "seek out actual domain expertise as the source of trustworthy information on topics you don't understand".
I deem these principles very basic to critical thinking/intelligence.
@dalias @larsmb @b_rain A few days ago, I started a thread complaining about leftists advocating the use of LLMs. A few people said something along the lines of them not really being leftists if they did.
After that, I saw posts about "vibe coding" from two socialists I've known for decades, both experienced software developers. One had just returned from a trip to Palestine, where he'd been a volunteer on the ground.
I loathe LLMs, but I can't just dismiss these people as fools. They're not.
@foolishowl @fabiocosta0305 @raffitz @larsmb @b_rain The non sequitur analogies from people who have no understanding of any of this but want to be armchair experts is so frustrating.
"The language is crusty and has difficulties you wouldn't encounter using a different language" is completely a different problem from "you are gluing together massive amounts of utterly random stolen code with no clue what it does and taking it as a matter of faith that it will safely do what you wanted it to do".
@dalias @jaystephens @larsmb @b_rain feels a bit "funny" to me that you seem to struggle so much with understanding how people fall for the corporate LLM sharade.
reading this thread looks like its the same for you as its its for them who struggle to grasp what LLM's actually do and what their problems are, just on another level.
like you wrote, they not getting that is their "vulnerability" and you not being able to get them is yours.
@glowl @jaystephens @larsmb @b_rain I've written elsewhere in the thread about how it's a vulnerabilty. What I take exception to is the idea that it's "late adopters" who are especially vulnerable to being bedazzled by the scam. I think it's plausible that they're *more* resilient on average, by virtue of not having been wowed by the previous "big thing" either.
My impression is that it's people with a proclivity for admiring authority and for wanting to be in in-groups who are most vulnerable to techno-futurist scams like "AI". They don't understand or care about the actual technology because their interest isn't in it, but in projecting an image of being someone who's in "club tech".
@larsmb thank you for standing up for your friends!
This "if they don’t know X" is fucking elitism.
To take up the point about doctors: those are the people who keep you alive when you need them.
I remember when my doctor saved my life by saying "go to the surgeon and get that toenail cut off *ASAP*".
It was infected and days later I’d have likely fallen prey to sepsis that could easily have killed me.
The doctor may not understand LLMs, but he knows how to keep me alive.
@dalias @b_rain
@larsmb @dalias @b_rain Recently LLMs, especially Gemini, have been getting new features that integrate web search (my understanding is that the LLM is in charge of a web clawler, collecting results that it then attempts to cite URLs directly), which may be the cause of some confusion here. It is obviously not a search engine, but IIRC the UI will usually say something like "Searching the web".
And I know I am not speaking to the right audience here, but this is a feature I actually stikes a sensible symbolic-subsymbolic balance between traditional "general, static" sort and what an LLM would generate anything that sounds like an answer.
@pkal Yes, I'm aware. The problem with that functionality is that it then throws that as additional context into the same system with the same constraints, so that doesn't really overcome the fundamental limitations.
¹ I know some of the "reasoning" models are enhanced to pull in additional context via searches and MCPs etc. The level of fail they still produce remains mind-blowing, because they then throw the additional context into the same statistical model with the very same limitations.
@larsmb @dalias @b_rain Agree.
Also, most experts like scientists, engineers and physicians aren’t used to be actively misled. Those fields are built on trusting everyone else’s expertise and assuming good intentions. It wouldn’t work otherwise. LLMs are a very different beast.
That’s also why there seems to be an uptick in completely fraudulent scientific publications. It’s relatively easy to do because the reviewers don’t immediately assume fraud.
@xerge @larsmb @b_rain "Also, most experts like scientists, engineers and physicians aren’t used to be actively misled."
LMAO. A good 75% or more (probably 90% now) of scientific publication is fraud (fabricated data, false citations, false authorship, plagiarism, etc.). Someone in the field who isn't paying attention enough to see that is lacking a basic skill they need to do their job.
I'm not saying you're wrong, just that ignorance of it doesn't absolve them.
As someone that has worked as a research scientist in chemistry for the last 30 years I can guarantee that the amount of fraudulent publications is a lot lower than that. Probably significantly below 10% in the hard sciences. Hard numbers are difficult to find.
It happens, but when it happens it is usually falsified data, that can only be caught by replication. Carelessness and mistakes obviously also happen.
Contemporary science (and engineering) is so complex that without trust nothing would work.
Some people do take advantage of that, but it remains pretty rare.
I suspect that those high numbers come out of some right-wing conspiracy mill and are part of the right-wing war on science (and on reality itself).
@larsmb @ridscherli @dalias @b_rain
Replace Torx with Phillips in the example above (talking to anyone who is not an experienced contractor).
It's very easy to get PH (Phillips) and PZ (Pozidriv) cross-head screws confused.
Each type was originally designed for different torque levels.
"To prevent slippage and damaging of screws, you should only use a Phillips head screwdriver on a Phillips head screw, and you should only use a Pozidriv screwdriver on a Pozidriv screw."
https://shop4fasteners.co.uk/blog/pozidriv-vs-phillips/
@dec23k @larsmb @dalias @b_rain
If
1. You have a very big phz screw
2. a small torx manual screw driver which exactly fits into the center
3. do not need much force on the screw
4. and are too lazy to go the basement for some real tools,
this might work. Tested for you :-)
And in my opinion this is a very good example for "knowing the limits of the tools". I know that it's not perfect and accept the limited results as they are without expecting more than possible or blaming others.




 )}]
)}]