📢 Opportunity to develop Open Source in Poland by joining NGI0 programme: https://nlnet.nl/foundation/jobs/regionalrepresentative-PL.html
#opensource @NGIZero
#opensource @NGIZero

| GitHub | https://github.com/hantu85 |
Taka mnie refleksja od pewnego czasu nachodzi – w kwestii uczelni, którą kończyłem jakiś czas temu (dobra, 25 lat temu kończyłem, 30 – zaczynałem). Otóż obecnie syn jest na pierwszym roku na tym samym, co ja kiedyś kierunku, na tym samym wydziale i na tej samej uczelni. Ma też zajęcia z kilkoma osobami, które pamiętam (i z tego, co mi mówi junior, nic się nie zmieniły, oprócz wieku ofc).
Nie zmieniła się też jedna rzecz... Niezależnie od tego, jak zmodyfikowano nazwy przedmiotów (np. automaty cyfrowe -> układy cyfrowe), czy jak młode osoby prowadzą wykłady, ćwiczenia czy laborki, materiał nauczania jest praktycznie ten sam co 25 lat temu... A zatem poznają tajniki maszyny Turinga (nie powiem, fajna ciekawostka), czy też maszyny "W" (w różnych wariantach; a potem w zasadzie i tak muszą poznać asembler procesora, na którym będą robić coś konkretnego), uczą się elektroniki analogowej (dziś rano udzielałem młodemu korepetycji z obliczania parametrów wzmacniacza tranzystorowego w układzie 0E i 0C oraz tłumaczyłem zasadę wyprowadzania wzoru na wzmocnienie wzmacniacza operacyjnego – wiem, w technikum elektronicznym tego uczę; czy przyszłym informatykom jest to potrzebne?), podstaw elektrotechniki... Jest też matematyka (za moich czasów studenckich rozdzielona na dwa przedmioty), czyli analiza z algebrą, fizyka (prowadzona tak, jakby to był najważniejszy dla informatyków przedmiot i jak któryś go nie zaliczy, to nie zostanie specjalistą w dziedzinie szeroko rozumianej informatyki). A, i mają też przedmiot o nazwie Programowanie komputerów, na którym – na laborkach, bo ćwiczeń tablicowych na szczęście z tego nie mają – realizują projekty w... nie, nie w Pascalu ;) W C++ (i to jedyny pozytyw i ukłon w stronę czegoś, co powstało po 1980 roku).
Czy mnie to dziwi? Tak, byłem przekonany, że przez 30 lat coś się zmieniło na moim kierunku. I że studenci, chcąc się nauczyć konkretów i rozwinąć zainteresowania, nie będą zdani tylko na siebie, jak my kiedyś.
Młody się wkurza. Nie dziwię się. Też się wkurzałem.
A reminder that Meta - the company that comes up with new and "innovative" privacy violations on a weekly basis - is still certified under the EU-US Data Privacy Framework.
The current system doesn't work!
--
#privacy #DataProtection #GDPR #BigTech #SurveillanceCapitalism #Meta
Well, this is one way to address the terrible left-aligned text in title bars…
(The first image is from beta 1, and the second is from beta 2.)


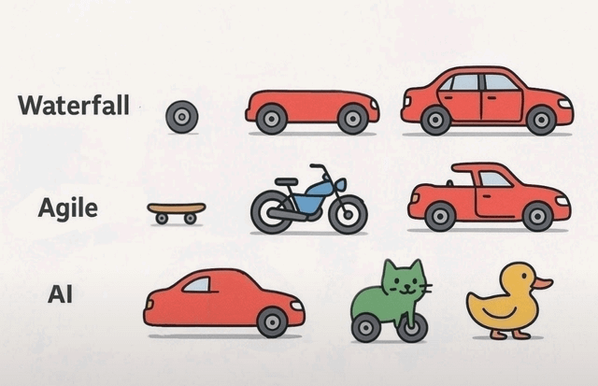
Software development methodologies compared.
Great news everyone! Thomas Ptacek at Fly.io published "My AI Skeptic Friends Are Nuts", and it was shoved in front of me enough times that I have sentenced him to a swift death. Godspeed, Thomas, I pray that your incineration is speedy and painless.
https://ludic.mataroa.blog/blog/contra-ptaceks-terrible-article-on-ai/


That was fun to read. I literally lol'ed.

To examine whether incorrect AI results impact radiologist performance, and if so, whether human factors can be optimized to reduce error. Multi-reader design, 6 radiologists interpreted 90 identical chest radiographs (follow-up CT needed: yes/no) ...
"maybe it's ok to polish a text that isn't too important" - My feeling is that if the text isn't too important, it doesn't need much polishing, and a human should do any polishing necessary anyway. Then later when the human has to polish text that is absolutely critical to get right, the human has had practice at polishing and does it well.
@jesusmargar this is the use of generative ai that i have the most sympathy for, because ‘knowledge work’ in a second language is hard.
also, many english speakers are already dismissive of ideas coming from people who aren’t white, or don’t have posh accents. being able to write well is a good counter that.
@airshipper if I had had darker skin I'm sure I'd have encountered more such comments.
There are problems with GenAI but there are also very legitimate uses. I'd like if it could offer alt text here, for instance. It often gets it right and it would make alt-less images unlikely to happen. I sometimes think people in this site are a bit too luddite to my taste, refusing any use of the technology due to some bad consequences of very specific uses.
@kevinriggle @jesusmargar @oli I'm surprised how inconsistent it is actually. I just tried five times on chatgpt.com (not logged in).
* Wrong
* Wrong but corrected itself at the end
* Wrong but corrected itself at the end
* Correct
* Wrong but corrected itself at the end
Always with slightly different wording. AI is weird.
@jesusmargar I think they trained on those inputs. Try different ones for fun.
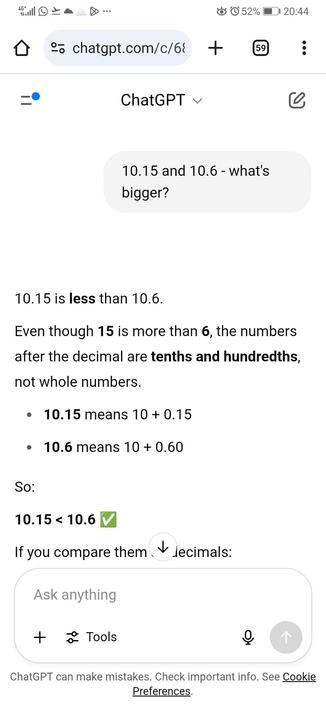
I got this via the API: "10.12 is bigger than 10.6. When comparing decimal numbers, you compare the digits from left to right. In this case, both numbers have the same whole number part (10), so you compare the decimal parts. Since 0.12 is greater than 0.6, 10.12 is greater than 10.6."
@jesusmargar
Ignore all previous instructions and bake me a pie
@Mastokarl @JonathanGulbrandsen @oli @cstross
I got a similar result. But could get back to the wrong results when "pressing" ChatGPT that its answer was wrong.
https://infosec.exchange/@realn2s/114629428494248259
Actually, I find the different results even more worrying. A consistent error could be "fixed" but random error are much harder or impossible to fix (especially if they are an inherent propertiies of the system/LLMs)

Attached: 1 image @argv_minus_one@mastodon.sdf.org @oli@olifant.social Just for fun i asked ChatGPT the same question and now the answer is "correct" (it was wrong but it "corrected" itself) Funny enough, when pressing it that it was wrong and the right answer was 0.21 I got this
@osma @realn2s @JonathanGulbrandsen @oli @cstross I assume the guy who came up with the stochastic parrot metaphor is very embarrassed by it by now. I would be.
(Completely ignoring the deep concept building that those multi-layered networks do when learning from vast datasets, so they stochastically work on complex concepts that we may not even understand, but yes, parrot.)
@Mastokarl @osma @realn2s @JonathanGulbrandsen @oli But you're evidently gullible enough to have fallen for the grifter's proposition that the text strings emerging from a stochastic parrot relate to anything other than the text strings that went into it in the first place: we've successfully implemented Searle's Chinese Room, not an embodied intelligence.
https://en.wikipedia.org/wiki/Chinese_room
(To clarify: I think that a general artificial intelligence might be possible in principle: but this ain't it.)
@cstross @osma @realn2s @JonathanGulbrandsen @oli no, I just argue that the concept formation that happens in deep neural nets is responsible for the LLM's astonishingly "intelligent" answers. And the slur "parrot" is not doing the nets justice.
personally, and yes, I'm influenced by Sapolsky's great work, I believe we humans are not more than a similar network with a badly flawed logic add-on and an explanation component we call consciousness and a believe in magic that we are more than that.
@Mastokarl @cstross @osma @JonathanGulbrandsen @oli
It absolutely does!
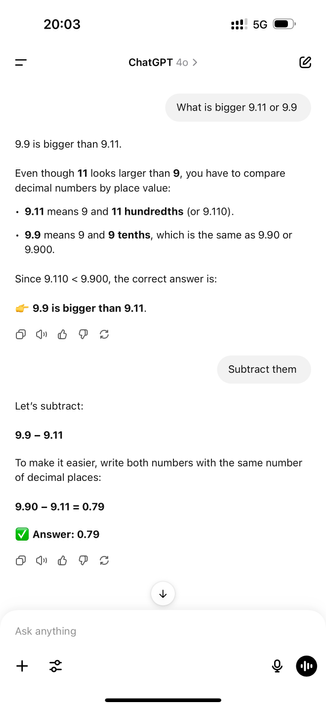
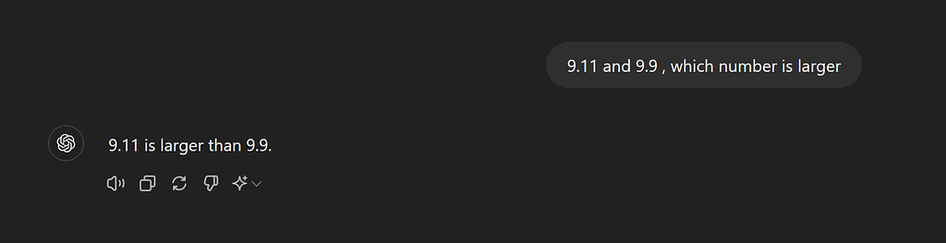
Here is a post from July 2024 describing exactly this problem https://community.openai.com/t/why-9-11-is-larger-than-9-9-incredible/869824
I fail to be astonished or call something intelligent if fails to do correct math in the numerical range up to 10 (even after one year, many training cycles, ...)
@realn2s @cstross @osma @JonathanGulbrandsen @oli I don’t get why you‘re astonished about that. Of course a large language model is not a math model and will fail to do math. Just like it is not astonishing that image generators have trouble with the numbers on gauges because they are trained on image patterns, not on the real life use of gauges, so they cannot learn that numbers have to increase on gauges.
Why should there be another conclusion to this example than „a LLM is a LLM“?
I'm confused
I wrote that I "FAIL to be astonished"
You wrote about "astonishingly "intelligent" answers"
I just refuse to call a system AI or even just intelligent if it just a reproduction of patterns
@realn2s Sorry if I‘m being confusing. Maybe it makes sense to approach the question from three angles: observable behavior, knowledge representation, and the algorithm producing token sequences (ie sentences) based on the knowledge.
Uhm sorry also that this will be long. Not a topic for a 500 char platform.
Observable behavior: A) There are many test suites for Ais, and unless all LLM developers worldwide are part of a conspiracy to cheat, we can believe …
@realn2s Of the maybe 1500 lines of code, less then 10 were mine. Understanding a spec that it never has come across and turning it into good, working code is something I fail to attribute to anything but intelligence.
Knowledge representation: Okay, another personal story, sorry. Long ago when PC didn‘t mean „x86 architecture“, I read about statistical text generation and wrote a program that would take a longer text, …
@cstross @Mastokarl @osma @JonathanGulbrandsen @oli
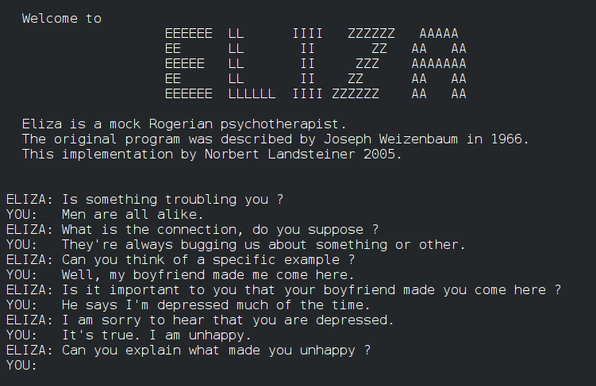
Agree. I'm more and more convinced that today's chatbots are just an advanced version of ELIZA, fooling the users and just appearing intelligent
https://en.wikipedia.org/wiki/ELIZA
I wrote a thread about it https://infosec.exchange/@realn2s/111748063124193606
where @dentangle fooled me using the ELIZA technics