I like how we took something computers were masters at doing, and somehow fucked it up.

@Mastokarl @JonathanGulbrandsen @oli @cstross
I got a similar result. But could get back to the wrong results when "pressing" ChatGPT that its answer was wrong.
https://infosec.exchange/@realn2s/114629428494248259
Actually, I find the different results even more worrying. A consistent error could be "fixed" but random error are much harder or impossible to fix (especially if they are an inherent propertiies of the system/LLMs)

Attached: 1 image @argv_minus_one@mastodon.sdf.org @oli@olifant.social Just for fun i asked ChatGPT the same question and now the answer is "correct" (it was wrong but it "corrected" itself) Funny enough, when pressing it that it was wrong and the right answer was 0.21 I got this
@osma @realn2s @JonathanGulbrandsen @oli @cstross I assume the guy who came up with the stochastic parrot metaphor is very embarrassed by it by now. I would be.
(Completely ignoring the deep concept building that those multi-layered networks do when learning from vast datasets, so they stochastically work on complex concepts that we may not even understand, but yes, parrot.)
@Mastokarl @osma @realn2s @JonathanGulbrandsen @oli But you're evidently gullible enough to have fallen for the grifter's proposition that the text strings emerging from a stochastic parrot relate to anything other than the text strings that went into it in the first place: we've successfully implemented Searle's Chinese Room, not an embodied intelligence.
https://en.wikipedia.org/wiki/Chinese_room
(To clarify: I think that a general artificial intelligence might be possible in principle: but this ain't it.)
@cstross @osma @realn2s @JonathanGulbrandsen @oli no, I just argue that the concept formation that happens in deep neural nets is responsible for the LLM's astonishingly "intelligent" answers. And the slur "parrot" is not doing the nets justice.
personally, and yes, I'm influenced by Sapolsky's great work, I believe we humans are not more than a similar network with a badly flawed logic add-on and an explanation component we call consciousness and a believe in magic that we are more than that.
@Mastokarl @cstross @osma @JonathanGulbrandsen @oli
It absolutely does!
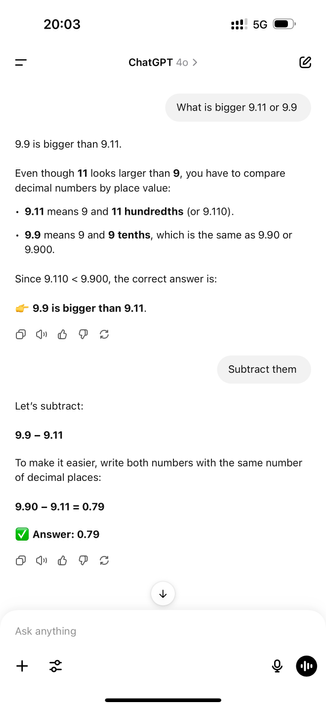
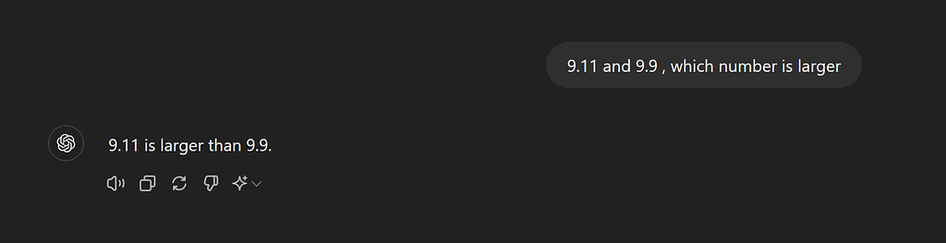
Here is a post from July 2024 describing exactly this problem https://community.openai.com/t/why-9-11-is-larger-than-9-9-incredible/869824
I fail to be astonished or call something intelligent if fails to do correct math in the numerical range up to 10 (even after one year, many training cycles, ...)
@realn2s @cstross @osma @JonathanGulbrandsen @oli I don’t get why you‘re astonished about that. Of course a large language model is not a math model and will fail to do math. Just like it is not astonishing that image generators have trouble with the numbers on gauges because they are trained on image patterns, not on the real life use of gauges, so they cannot learn that numbers have to increase on gauges.
Why should there be another conclusion to this example than „a LLM is a LLM“?
I'm confused
I wrote that I "FAIL to be astonished"
You wrote about "astonishingly "intelligent" answers"
I just refuse to call a system AI or even just intelligent if it just a reproduction of patterns
@realn2s Sorry if I‘m being confusing. Maybe it makes sense to approach the question from three angles: observable behavior, knowledge representation, and the algorithm producing token sequences (ie sentences) based on the knowledge.
Uhm sorry also that this will be long. Not a topic for a 500 char platform.
Observable behavior: A) There are many test suites for Ais, and unless all LLM developers worldwide are part of a conspiracy to cheat, we can believe …
@realn2s Of the maybe 1500 lines of code, less then 10 were mine. Understanding a spec that it never has come across and turning it into good, working code is something I fail to attribute to anything but intelligence.
Knowledge representation: Okay, another personal story, sorry. Long ago when PC didn‘t mean „x86 architecture“, I read about statistical text generation and wrote a program that would take a longer text, …
@realn2s that you just can‘t remember the chorus of? Pretty parroty, right?
If you made it so far, thanks for reading, would love to hear your thoughts on this.
And apologies for the length. But I couldn’t do it shorter (yes I could ask an AI to summarize it :) ).
@Mastokarl
And this is where I disagree.
The current AI system have no clue about semantics; they just have such a large context of syntax that it seems like semantics.
To illustrate it imagine a magician.
A hobbyist magician might make a handkerchief disappear. David Copperfield making the Statue of Liberty disappear, or Franz Harary vanishing Tower Bridge is a whole different level. But it's no magic. nevertheless.
And regarding you tetris example.
Asking and LLM to write a novel let's say in style of Ernest Hemingway wile give a result. Searching will reveal that this novel was never written before.
Thats neither creative, intelligence or impressive. Actually, if a human would do it would be plagiarism (and if it was sold off as previously unknown work of Ernest Hemingway it would be forgery).
So, the question is not, if the LLM can write a game which hasn't been written before in this exact version.
The question is, could the "AI" have developed Pong before it was created, Tetris before Tetris was a thing, Wolfenstein 3d before it was envisioned, or Portal before it existed.
I'm quite sure that the answer is no.