I want to see if the thoughts of others align with mine.
An FPGA toolchain should optimise for:
An FPGA toolchain should optimise for:
highest worst-case Fmax
highest average Fmax
highest best-case Fmax
Poll ended at .
@lofty If I'm comparing RTL changes for fmax then I'll usually do ~100 runs and take the median. Seems reasonable because 8 runs aiming for median frequency should have only a 0.4% chance of all failing. Most client machines have 8 parallel threads of execution available these days.
I don't particularly care about the mean because if I get a worst-case result then you can bet I'm re-rolling, so the tail values don't matter.
I don't think it's *good* that seed sweeping is the optimal way of using the tools, but the fact is it reduces variance as well as increasing expected fmax.
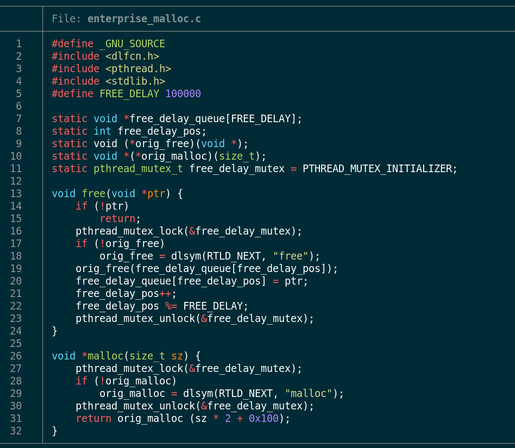
@acsawdey @azonenberg @mei @lofty > This same thing would be a tool for finding these errors if you add code to fill freed blocks with provocatively bad data
Isn't this what asan does with quarantining?
@wren6991 @azonenberg @mei @lofty yeah there are lots of things that do this, sometimes you have to roll your own .. like for instance if you can’t rebuild with asan.
I think it’s axiomatic that useful programming tools get reimplemented all the time.
@acsawdey @wren6991 @mei @lofty yeah it's more the horror of "let's just double all allocations and add a fudge factor in the expectation that the thing is full of buffer overflows" and "delay all frees in the expectation that it's full of UaFs".
Vivado leaks memory bad enough as is. I'd want another 128GB of RAM if I was using this...
@wren6991 @azonenberg @acsawdey @mei @lofty I have in fact fed 128GB chunk after 128GB chunk of swap to a tool that ate all 64GB of ram and then lots more. (I soon had to switch to 256GB chunks) I don't remember how many I carved out of my SSD in the end, but I know it was only a 1TB SSD and I don't think I pulled any from spinning rust. It did eventually finish though. :P
And this wasn't even a Vendor tool, it was "research grade" tooling written in python.
@nullenvk @lofty
when I was taking the Adanced Operating Systems class by @mwk, she once told a story how ISE had use-after-free bugs and in order to make it work, she had to use an LD_PRELOAD library that remembered what pointers ISE tried to free, and freed them a few calls later.
Which is part of what the code @mei posted does
@[email protected] @[email protected] Oh, ok. Didn’t know the exceptions of static.
__attribute__((constructor)) to install a SIGSEGV handler to just quietly "make the problem go away" a la https://people.csail.mit.edu/rinard/paper/osdi04.pdf (might also need to shim signal(2) and sigaction(2) to make sure it stays in place in case the Serious Enterprise Software tries to install its own crash handlers).
@cliffordheath @mei @lofty @wren6991
Yeah that's what I was thinking. Just loop over the area and free everything that isn't null.
I was just wondering if there was some interaction between valgrind and LD_PRELOAD that obviated it.
I like how this is called "enterprise malloc"