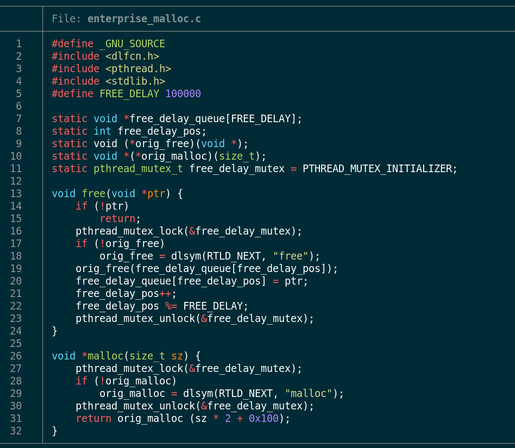
I want to see if the thoughts of others align with mine.
An FPGA toolchain should optimise for:
An FPGA toolchain should optimise for:
highest worst-case Fmax
highest average Fmax
highest best-case Fmax
Poll ended at .
@lofty If I'm comparing RTL changes for fmax then I'll usually do ~100 runs and take the median. Seems reasonable because 8 runs aiming for median frequency should have only a 0.4% chance of all failing. Most client machines have 8 parallel threads of execution available these days.
I don't particularly care about the mean because if I get a worst-case result then you can bet I'm re-rolling, so the tail values don't matter.
I don't think it's *good* that seed sweeping is the optimal way of using the tools, but the fact is it reduces variance as well as increasing expected fmax.