NVIDIA (@nvidia)
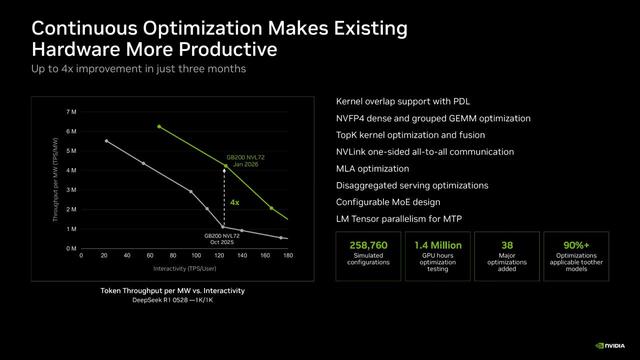
NVIDIA 플랫폼 위에서 Dynamo, SGL, TensorRT LLM, vLLM 같은 오픈소스 및 추론 도구들이 지속적으로 최적화되고 있다고 밝혔다. 개발자 생태계의 개선을 통해 토큰 출력 품질과 비용 효율이 계속 향상된다는 점이 핵심이다.
NVIDIA (@nvidia) on X
Open-source software never stops. It only accelerates. Dynamo, @sgl_project, TensorRT LLM, and @vllm_project are constantly optimized by a vast ecosystem of developers building on top of the NVIDIA platform. The result: your token output keeps improving and token cost keeps







