Attachment Dedup Hash
Stop duplicate uploads by hashing attachments.
#php #python #dedup #uploads #hashing #storage #performance #backendsafety #reliability #viralcoding

Attachment Dedup Hash
Stop duplicate uploads by hashing attachments.
#php #python #dedup #uploads #hashing #storage #performance #backendsafety #reliability #viralcoding
[Перевод] Дедупликация в OpenZFS теперь хороша, но использовать её не стоит
Вот-вот выйдет релиз OpenZFS 2.3.0 с новой функцией Fast Dedup . Это огромный шаг вперёд по сравнению со старой дедупликацией и отличный фундамент для будущих доработок. Контрибьютор OpenZFS @gmelikov и команда VK Cloud совместно перевели статью об этом релизе, в которой новая функция сравнивается со старой дедупликацией и описывается максимально подробно с практическими примерами. В 2023–2024 коллеги из Klara много работали над этой функцией, и мы согласны с ними, что она весьма хороша! После релиза Fast dedup на многих ресурсах в обсуждениях продолжили писать, что «новый дедуп всё так же плох, он требует столько же ОЗУ и также убивает производительность». Но эта информация лишь отчасти близка к правде и повторяет всё тот же мотив, который когда-то кто-то озвучивал на форумах. Винить в этом никого не хочется. И не стоит, так как дедупликация в OpenZFS и правда была очень требовательной к правильному применению. Найти качественные гайды тоже не просто, ответ по умолчанию — «не используйте её» — был и (в целом) остаётся правильным. Но, по прошествии почти 20 лет жизни дедупа в OpenZFS, настало время вернуться к этому вопросу. Посмотрим на свежую информацию об имплементации дедупа в OpenZFS, как он работал до улучшений, в чём была его проблема, что поменяли в fast dedup, и почему же это всё ещё не дефолт.
https://habr.com/ru/companies/vk/articles/863904/
#zfs #openzfs #reflink #dedup #storage #filesystem #deduplication
Дедупликация данных в Windows 10 и Windows 11 средствами Microsoft
Сегодня я кратко расскажу вам как включить дедупликацию данных в клиентских ОС - Windows 10 и Windows 11, добавив функционал из Windows Server, причем не какие-то сторонние бинарники, а оригинальные, подписанные файлы Microsoft, которые к тому же будут обновляться через Windows Update. В этой статье не будет описания дедупликации данных, - разве что совсем кратко что это такое, и не будет сравнения решений разных вендоров. Я дам ниже ссылки на достойные, на мой взгляд, статьи других авторов и готов буду отвечать на вопросы, если их зададут ниже в виде комментария или в ПМ. Начать знакомство рекомендую с базовой теории Введение в дедупликацию данных / Хабр (habr.com) от компании Veeam, затем почитать о том, что такое дедупликация Microsoft - Обзор и настройка средств дедупликации в Windows Server 2012 / Хабр (habr.com) - статья моего бывшего коллеги по Microsoft Георгия говорит о том, как настраивается дедупликация NTFS в Windows Server 2012. В последующих изданиях Windows Server 2012R2, 2016, 2019, 2022 и 2025 функционал развивался, появилась поддержка ReFS, стало возможно (неочевидным способом) дедуплицировать системный том, расширились компоненты управления, - но для конечного пользователя все остается там же. Установили одним кликом, включили для диска, забыли. В заключение подготовительной информации - тем кого действительно интересует кроссплатформенные решения и их сравнения, предложу ознакомиться со статьей Илии Карина - Dedup Windows vs Linux, MS снова “удивит”? / Хабр (habr.com) - его не должны заподозрить в рекламе Microsoft, его сравнение подходов, и результат меня самого удивил. У меня на такую большую исследовательскую работу сил и возможностей нет, - почитайте. И имейте в виду, что если вы используете последний Windows 11, то и компоненты дедупликации в нем будут последние, от Windows Server 2025, то есть с еще более впечатляющим результатом.
What do people use to do #offsite #backups with?
Currently I have a #zfs pool, on which I take a daily snapshot of certain datasets, clone them, and send those using #restic to a #hetzner #storagebox (with #encryption, #dedup and #compression activated).
Currently I have snapshots going back to mid 2022, which are being pruned according to a schedule, but I've already exceeded 5TB of storage.
I'd like something that'd perhaps slightly less convoluted, but also doesn't break the bank. I'd love to use straight ZFS #replication but that is priced out of my budget.
A new benchmark for data 📚
Rather than test if a model is good
This tests whether you can filter data
360 languages
They also share metrics for data redundancy if you want just those
https://arxiv.org/abs/2311.06440
https://github.com/toizzy/
#data #preprocessing #dedup #enough2skim #NLP #NLProc


Data quality is a problem that perpetually resurfaces throughout the field of NLP, regardless of task, domain, or architecture, and remains especially severe for lower-resource languages. A typical and insidious issue, affecting both training data and model output, is data that is repetitive and dominated by linguistically uninteresting boilerplate, such as price catalogs or computer-generated log files. Though this problem permeates many web-scraped corpora, there has yet to be a benchmark to test against, or a systematic study to find simple metrics that generalize across languages and agree with human judgements of data quality. In the present work, we create and release BREAD, a human-labeled benchmark on repetitive boilerplate vs. plausible linguistic content, spanning 360 languages. We release several baseline CRED (Character REDundancy) scores along with it, and evaluate their effectiveness on BREAD. We hope that the community will use this resource to develop better filtering methods, and that our reference implementations of CRED scores can become standard corpus evaluation tools, driving the development of cleaner language modeling corpora, especially in low-resource languages.
Forwarder in place. Now migrating my email folders to the new IMAP.
I was never an intricate labels user, but there will still be enough dups to make https://github.com/quentinsf/IMAPdedup worthwhile, probably
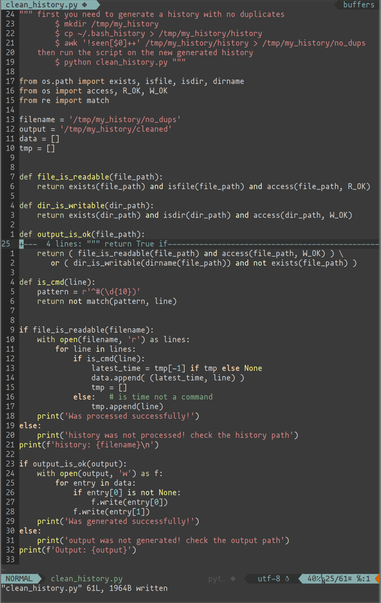
I needed to remove all duplicates from ~/.bash_history, and since it contains the date and time for each command, I ended up with lots of dates and times with no commands (since they were duplicates and got removed).
And I didn't want to check 34k+ of lines manually. So, I wrote a Python script to solve that.
in case you're interested, here is the code: https://gitlab.com/ds.python/useful-scripts
#BASH #history #bashhistory #python #duplicates #duplicate #dedup #code #python3 #linux #gnulinux
https://log.pyratebeard.net/entry/20221101-smoke_me_a_kipper.html
smoke me a kipper - having to put my backups to the test in a real-life scenario
47/100 #100daystooffload
https://log.pyratebeard.net/entry/20220414-speak_of_the_dedup.html
speak of the dedup - backup, backup, backup
31/100 #100daystooffload




