So many warn that evaluating with GPT favors GPT
(or any LLM evaluating itself).
Now it is also shown
Science, not just educated guesses
(Fig: T5, GPT, Bart each prefer their own) https://arxiv.org/abs/2311.09766
#enough2skim #scientivism #NLP #nlproc #GPT #LLM #eval #data


LLMs as Narcissistic Evaluators: When Ego Inflates Evaluation Scores
Automatic evaluation of generated textual content presents an ongoing challenge within the field of NLP. Given the impressive capabilities of modern language models (LMs) across diverse NLP tasks, there is a growing trend to employ these models in creating innovative evaluation metrics for automated assessment of generation tasks. This paper investigates a pivotal question: Do language model-driven evaluation metrics inherently exhibit bias favoring texts generated by the same underlying language model? Specifically, we assess whether prominent LM-based evaluation metrics (e.g. BARTScore, T5Score, and GPTScore) demonstrate a favorable bias toward their respective underlying LMs in the context of summarization tasks. Our findings unveil a latent bias, particularly pronounced when such evaluation metrics are used in a reference-free manner without leveraging gold summaries. These results underscore that assessments provided by generative evaluation models can be influenced by factors beyond the inherent text quality, highlighting the necessity of developing more reliable evaluation protocols in the future.
A new benchmark for data 📚
Rather than test if a model is good
This tests whether you can filter data
360 languages
They also share metrics for data redundancy if you want just those
https://arxiv.org/abs/2311.06440
https://github.com/toizzy/
#data #preprocessing #dedup #enough2skim #NLP #NLProc


Separating the Wheat from the Chaff with BREAD: An open-source benchmark and metrics to detect redundancy in text
Data quality is a problem that perpetually resurfaces throughout the field of NLP, regardless of task, domain, or architecture, and remains especially severe for lower-resource languages. A typical and insidious issue, affecting both training data and model output, is data that is repetitive and dominated by linguistically uninteresting boilerplate, such as price catalogs or computer-generated log files. Though this problem permeates many web-scraped corpora, there has yet to be a benchmark to test against, or a systematic study to find simple metrics that generalize across languages and agree with human judgements of data quality. In the present work, we create and release BREAD, a human-labeled benchmark on repetitive boilerplate vs. plausible linguistic content, spanning 360 languages. We release several baseline CRED (Character REDundancy) scores along with it, and evaluate their effectiveness on BREAD. We hope that the community will use this resource to develop better filtering methods, and that our reference implementations of CRED scores can become standard corpus evaluation tools, driving the development of cleaner language modeling corpora, especially in low-resource languages.
🤖: Detecting if chatGPT made this text...
It did not
A survey on the (few) datasets and methods to detect it
https://arxiv.org/abs/2309.07689
(not sure why chatGPT and not LLM in general, but NVM)
#enough2skim #NLP #nlproc #chatgpt #LLM #LLMs #AGI
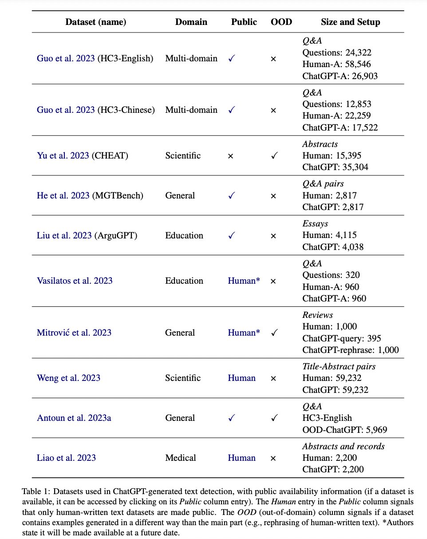
Detecting ChatGPT: A Survey of the State of Detecting ChatGPT-Generated Text
While recent advancements in the capabilities and widespread accessibility of
generative language models, such as ChatGPT (OpenAI, 2022), have brought about
various benefits by generating fluent human-like text, the task of
distinguishing between human- and large language model (LLM) generated text has
emerged as a crucial problem. These models can potentially deceive by
generating artificial text that appears to be human-generated. This issue is
particularly significant in domains such as law, education, and science, where
ensuring the integrity of text is of the utmost importance. This survey
provides an overview of the current approaches employed to differentiate
between texts generated by humans and ChatGPT. We present an account of the
different datasets constructed for detecting ChatGPT-generated text, the
various methods utilized, what qualitative analyses into the characteristics of
human versus ChatGPT-generated text have been performed, and finally, summarize
our findings into general insights
Predictions throughout training, hyperparams and architectures are yet again shown to be on
a small manifold
which means models learn their classifications outputs similarly
https://arxiv.org/abs/2305.01604
Mao ... @pratikac
#MachineLearning #enough2skim
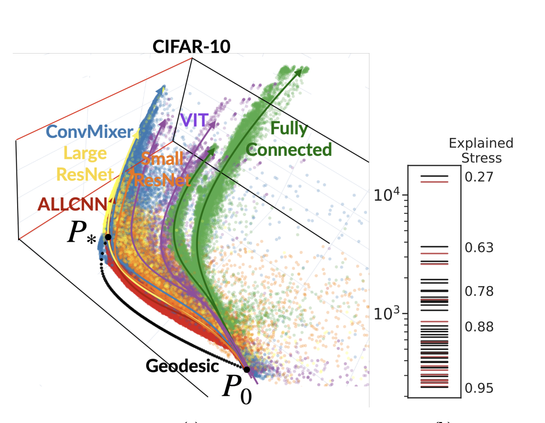
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
Few-shot learning almost reaches traditional machine translation
https://arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
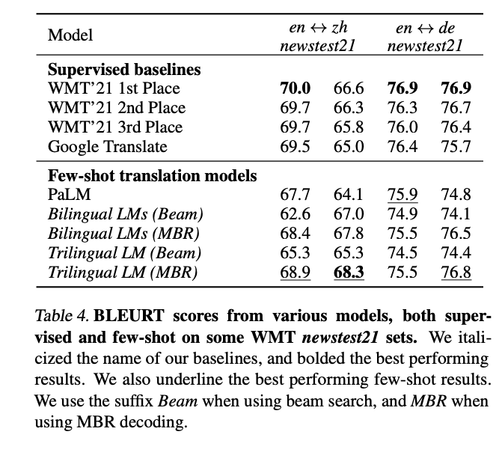
The unreasonable effectiveness of few-shot learning for machine translation
We demonstrate the potential of few-shot translation systems, trained with
unpaired language data, for both high and low-resource language pairs. We show
that with only 5 examples of high-quality translation data shown at inference,
a transformer decoder-only model trained solely with self-supervised learning,
is able to match specialized supervised state-of-the-art models as well as more
general commercial translation systems. In particular, we outperform the best
performing system on the WMT'21 English - Chinese news translation task by only
using five examples of English - Chinese parallel data at inference. Moreover,
our approach in building these models does not necessitate joint multilingual
training or back-translation, is conceptually simple and shows the potential to
extend to the multilingual setting. Furthermore, the resulting models are two
orders of magnitude smaller than state-of-the-art language models. We then
analyze the factors which impact the performance of few-shot translation
systems, and highlight that the quality of the few-shot demonstrations heavily
determines the quality of the translations generated by our models. Finally, we
show that the few-shot paradigm also provides a way to control certain
attributes of the translation -- we show that we are able to control for
regional varieties and formality using only a five examples at inference,
paving the way towards controllable machine translation systems.
20 questions can now be played by computers
you probably all know @[email protected] that can guess what you thought about
https://arxiv.org/pdf/2301.08718.pdf
propose the other role
They pick a character and will answer yes or no
(basically, QA over wiki+ tweaks)
#enough2skim