Behold the AI bots that Cloudflare blocked from this blog
I don’t like writing for free–social media blatantly excepted–so when I watched a panel at Web Summit in mid-November about the effect of AI-model crawlers on news-site revenue and the Pay Per Crawl initiative that Cloudflare was proposing as a solution, I had to take notes.
Then a few weeks after I got home from Lisbon, I realized I could take action: While Pay Per Crawl remains in an invitation-only beta test, Cloudflare’s AI Crawl Control is open to the public and included in that Internet infrastructure firm’s free tier. Then I learned that it’s shockingly easy to add Cloudflare’s services to a WordPress.com blog.
Crawl Control comes with a preset list of bots to block and bots to allow, grouped by type: “AI Assistant” bots that take action in response to user requests are fine; “AI Search” bots that support “AI-driven search experiences” are also okay (contrary to Cloudflare CEO Matthew Prince’s discussion of them in that Web Summit panel); “AI Crawler” bots that collect content for training AI models are not.
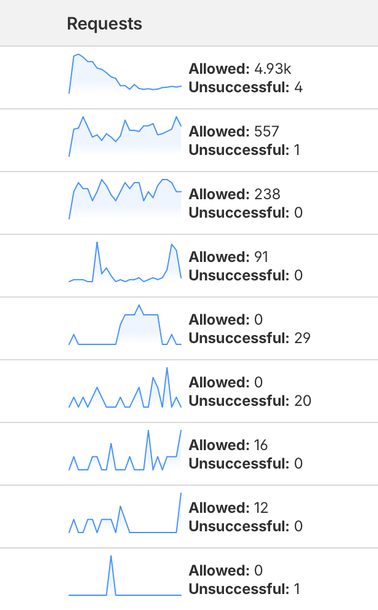
I took a screenshot of this part of my Cloudflare dashboard at almost the same time each afternoon this week, and these are my totals:
- Huawei’s PetalBot was the highest-volume AI crawler, with Cloudflare reporting 224 “unsuccessful” request attempts from that Chinese tech giant’s AI crawler (Cloudflare doesn’t take direct credit for blocking bots in this interface), followed by Anthropic’s Claude-SearchBot, with 165 unsuccessful requests.
- Among AI assistants, the second-highest category by volume, OpenAI’s ChatGPT-User had 1,251 allowed requests, DuckDuckGo’s DuckAssistBot had 36 allowed, and Perplexity’s Perplexity-User had one unsuccesful request.
- The top bot in AI search came from an unlikely place: Apple’s Applebot, with 734 allowed. OpenAI’s OAI-SearchBot was far behind, with 128 allowed requests, while Perplexity’s PerplexityBot had all eight request attempts fail.
To put this in context, the top two search engine crawlers had exponentially higher numbers. Google’s Googlebot somehow racked up a little over 20,000 requests, more than 30 times the presumably-human traffic I see in my WordPress dashboard here for the last five days, and 23 failed requests. Microsoft’s Bingbot came in second with 3,003 allowed requests and two unsuccessful ones.
As Cloudflare’s CEO complained in that Web Summit panel, Googlebot feeds into both Google’s traditional search and the AI Overview search results that Web publishers now blame for dangerous declines in their search traffic. There’s nothing I can do about that from this side of the screen except hope that Cloudflare’s Pay Per Crawl efforts and other advocacy efforts stir some rethinking at Google.
But I can’t tell you how well Pay Per Crawl works, because almost three weeks after applying to join the private beta I’m still waiting for my invitation. I imagine I’ll be waiting much longer before an AI-crawler operator decides that my tiny contribution to the Web’s collective content is worth sending me some money.
#AI #AIBot #AICrawlControl #AICrawler #Amazon #Applebot #Bingbot #ChatGPT #Cloudflare #Huawei #OpenAI #PayPerCrawl #Petalbot