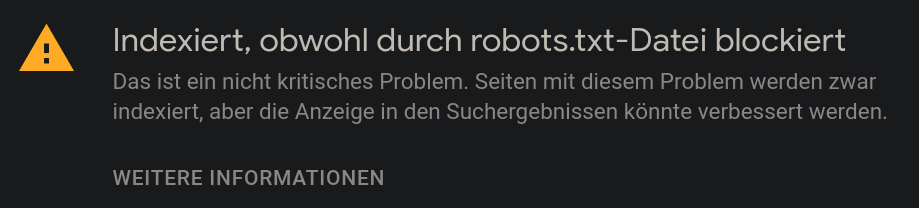
Guests on our own web
A few months ago I spun up a new VPS on Linode, London datacentre. Nothing special – Debian, Nginx, a Let's Encrypt certificate, a domain I was going to use for my daily notes and my homelab experiments. No link posted anywhere, no entries in my feeds, no backlinks from the sites I run. Just a freshly assigned IP, from a subnet that a week earlier had belonged to someone else.
[...]