Bessere KI-Antworten – auch ohne Hochleistungsrechner
KI-Systeme, die Texte nicht nur generieren, sondern gezielt in Dokumenten recherchieren, sind mittlerweile etablierter Stand der Technik. Einer dieser Ansätze heißt Retrieval-Augmented Generation (RAG): Stellt ein Benutzer eine Frage, sucht das System relevante Informationen in einer Wissensbasis – zum Beispiel in einem Wiki – und nutzt diese als Grundlage, um relevante Inhalte bzw. Quellen aufzulisten oder mittels KI Antworten daraus zu generieren.
Das Problem: Damit ein solches System gut funktioniert, müssen viele Stellschrauben richtig eingestellt werden. Diese sogenannte Hyperparameter-Optimierung ist normalerweise entweder zeitaufwändig oder rechenintensiv und in jedem Fall technisch anspruchsvoll. Unsere aktuelle Untersuchung zeigt jedoch: Eine automatisierte Optimierung ist möglich – sogar auf einem normalen Laptop.
Ausgangslage
Grundlage unserer Untersuchung im Open Science Lab war die Weiterentwicklung unseres RAG-Moduls für Wikibase4Research. Mit dem zuvor bestehenden System war es bereits sehr einfach möglich, eine Mediawiki Installation zu erhalten, deren Inhalte KI-gestützt via RAG durchsuchbar sind. Egal ob es nun um Artikelseiten in einem einfachen Mediawiki, strukturierte Wissensdaten in einer Wikibase oder eine Kombination aus beidem wie zum Beispiel Semantic Mediawiki oder Semantic Wikibase geht.
Eine Einführung in die grundlegende Funktionsweise von RAG und Wikibase4Research liefert das folgende Video:
Um eine hohe Qualität der KI-basierten Suchergebnisse und Antworten zu erhalten, ist es aber nötig, das System entsprechend der verwendeten Daten zu konfigurieren. Für diese Einstellungen gibt es keine Standardfälle, es gehört in das Arbeitsfeld eines Data Scientist die Systemparameter zu testen und zu verbessern. In diesem Prozess wird daher klassisch ein hohes Maß an Erfahrung und Fachwissen benötigt, um optimale Ergebnisse zu erhalten.
Die Alternative ist der nun in Wikibase4Research integrierte AutoRAG Ansatz, der die Parameter vollautomatisch optimiert. Dieser Prozess wird im Farchjargon „Hyperparameter Tuning“ oder auch „Hyperparameter Optimierung“ genannt.
Anforderungen
Die Rahmenbedingungen für ein Hyperparameter Tuning können sehr unterschiedlich sein. In unserem Fall ergeben sich die Anforderungen vor allem aus der Nutzergruppe von Wikibase4Research.
Forscher/Innen
Im Forschungskontext haben wir es mit fächerspezifischen Daten zu tun. Die beteiligten Wissenschaftler sind Experten in ihrer jeweiligen Fachdomäne. Expertise im Bereich spezieller Data-Science-Anwendungen ist in den Projektteams meist nicht vorhanden. Dies ist durchaus sinnvoll, denn das Projektteam ist somit auf die im Projekt zu bearbeitenden Forschungsfragen spezialisiert.
Daten
Für die Optimierung wird ein Test-Datensatz benötigt, der mögliche Fragen (Suchanfragen) mit den optimalen Quellen in den Daten verknüpft. Dieser Datensatz wird mit den Suchergebnissen des Systems verglichen, um die Qualität der Systemeinstellung bewerten zu können (Idealdaten). Solche Testdaten liegen in den überwiegenden Fällen nicht vor.
Endnutzer/Innen
Wer nutzt die Daten letztendlich und welche Art von Anfragen werden gestellt? Diese Frage ist entscheidend bei der Optimierung. Werden die Endnutzer spezifische Fakten aus den Daten abfragen wie zum Beispiel Jahreszahlen bestimmter Ereignisse oder eher Zusammenfassungen ganzer Absätze oder Artikel erwarten? Zu welchen Themen werden voraussichtlich Fragen gestellt? Erwarte ich eher Fragen zum Inhalt der Daten oder Fragen auf der Metaebene wie zum Beispiel zur Anzahl von Quellen, der Struktur und Länge von Texten, des Schreibstils oder zur Medienart? Werden Suchanfragen von Wissenschaftlern im Fachjargon gestellt oder eher in Umgangssprache formuliert? Die frühzeitige Definition grundlegender Personas für die zu erwartende Nutzergruppe hilft nicht nur bei der Optimierung von RAG, sondern ist auch ein wichtiger Schritt bei der Erstellung von Design und Benutzeroberflächen in der Präsentation der Forschungsergebnisse.
Infrastruktur
Hohe Rechenkapazitäten, Zugang zu GPU-Processing und Budget für industrielle KI-Services ist in vielen Projekten nicht vorhanden. Wikibase4Research bietet die Option, externe Schnittstellen wie Huggingface, OpenAI oder die SAIA-Umgebung der GWDG zur Ausführung von KI-Modellen zu nutzen. Die dort bestehenden Limits für kostenlose Nutzung reichen aber meist nicht aus, um die Vielzahl an Parameter-Konfigurationen zu testen, die zur Optimierung eines RAG-Systems notwendig ist. Ideal wäre also, die Ausführung lokal auf allgemein verfügbarer Hardware durchführen zu können, was auch unter dem Aspekt der ressourcenschonenden Nutzung von KI ein erstrebenswertes Ziel ist.
Es ergibt sich für unseren Ansatz daher folgender Anforderungskatalog:
- Anpassung auf die verwendeten Daten
- vollautomatische Optimierung
- keine technischen Vorkenntnisse nötig
- Test-Datensatz wird generiert
- User-Persona-Profile berücksichtigen
- möglichst effizient, mit geringem Ressourcenbedarf
Methodik
Daten
Als Datengrundlage dienten jeweils 50 zufällige Artikel aus drei MediaWiki-basierten Wissenssammlungen:
Um die Qualität der Suche zu bewerten, wurden automatisch Frage-Kontext-Antwort-Tripel erzeugt. Zum Einsatz kam dafür das mehrsprachige Sprachmodell IBM Granite 4 350M Nano, das speziell für Umgebungen mit geringer Rechenleistung wie zum Beispiel für On-Device-Anwendungsfälle entwickelt wurde.
LLM-Prompt
Um hinsichtlich der erwarteten Nutzung realistische Fragen zu generieren, wurde der an das Modell gelieferte Prompt („Erstelle Fragen aus dem Seiteninhalt“) um speziell angepasste Rollenbeschreibungen (Personas) ergänzt, die per Konfigurationsdatei individualisiert werden können. Eine solche Persona-Definition könnte zum Beispiel lauten: „You are a scientist who wants to learn about historic manorhouses in Europe“.
Parameter
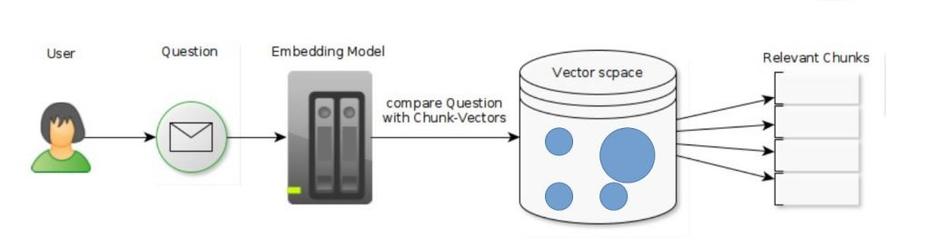
In einem RAG-Prozess werden die zu durchsuchenden Daten in einer speziellen Datenbank indiziert, um später schnell und effizient relevante Inhalte zu finden.
Information Extraction und Indizierung von Daten in einem RAG-Prozess
Die meisten von uns verwendeten Parameter optimieren diesen Prozess der Informations Extraktion (IE). Dabei wird bestimmt, in welcher Form die Daten gespeichert werden und ob diese ggf. vor dem Speichern um Metadaten wie Schlagworte, Titel oder Zusammenfassungen ergänzt werden. Für die Vektorisierung verwendeten wir das Modell Qwen3-embedding:0.6B. Die mittels AutoRAG optimierten Parameter sind im Folgenden aufgelistet:
- Chunk_Size: Wie groß sind die Informationsabschnitte, die später zugreifbar sein sollen?
- Chunk_Overlap: Wie stark überlappen sich die Informationsabschnitte?
- Extractors: Welche Datenanreicherungen sollen erfolgen (zum Beispiel Zusammenfassung erstellen, Fragen generieren)?
- Top_K: Wieviele Chunks werden als Suchergebnis geliefert?
Sind die Daten eingelesen und wird eine Suchanfrage gestellt, wird das System nach relevanten Informationsabschnitten durchsucht. Dieser Prozess wird „Information Retrieval“ genannt. Man kann es mit den Ergebnissen einer Google-Suche vergleichen, bei der die relevantesten Ergebnisse nicht zwangsläufig an erster Stelle der Liste stehen.
Information Retrieval in einem RAG Prozess
Information Retrieval bedeutet, zur Frage des Nutzers relevante Informationen zu finden. In diesem Prozessschritt optimieren wir den Parameter „Top_K“, der definiert, wie viele der Suchergebnisse im weiteren Prozess berücksichtigt werden. Ist Top_K zu klein, sind wichtige Quellen eventuell nicht enthalten. Ist Top_K zu groß, verarbeitet man eventuell eine große Menge wenig relevanter Inhalte.
Optimierungsverfahren
Statt alle möglichen Kombinationen auszuprobieren (was sehr lange dauern würde), kommt ein Suchalgorithmus zum Einsatz, der die verschiedenen Parameter stufenweise verbessert. Dieses als Greedy („gierig“) benannte Verfahren optimiert zunächst nur einen einzigen Parameter, dann den nächsten usw. Wir verzichten damit auf optimale Lösungen, erreichen aber hinreichend gute Ergebnisse mit akzeptablem Aufwand.
Als Bewertungsmaß für die Optimierung dient dabei der sogenannte Mean Reciprocal Rank (MRR) – ein Maß dafür, an welcher Position relevante Inhalte in der Trefferliste platziert sind. Ein entscheidender Vorteil:
Die Bewertung erfolgt vollständig ohne KI-Antwortgenerierung. Es wird also nur getestet, wie gut das System relevante Inhalte findet, nicht wie gut eine KI daraus später Antworten generiert. Dadurch wird erheblich Rechenzeit gespart.
Antwort Generierung in einem RAG Prozess. Diese Phase wurde in der Optimierung NICHT berücksichtigt
Technische Umsetzung
Die Implementierung erfolgte vollständig im MediaWiki-Umfeld mit:
- Wikibase4Research
- einer Docker-basierten Python-API
- dem RAG-Framework LlamaIndex
- lokaler Modellbereitstellung über Ollama
Die Experimente liefen auf einem handelsüblichen Laptop aus dem Jahr 2022 (Dell Latitude 5421, Intel Core i7-11850H mit 8 Kernen, 16 GB RAM) – ohne GPU-Beschleunigung.
Ergebnisse
Trotz der bewusst schlanken Hardware-Ausstattung konnte die Optimierung meist bereits innerhalb einer Stunde abgeschlossen werden. Dabei wurde bei allen Datensätzen eine starke Verbesserungen der Abfrageergebnisse erzielt.
Für unser Qualitästmaß, den Mean Reciprocal Rank (MRR), ergab sich eine Steigerung von durchschnittlich 12 bis 25 Prozent gegenüber den voreingestellten Parametern. Das bedeutet, in den Ergebnissen der Suchanfrage waren mehr relevante Quellen aufgeführt und relevante Quellen standen in der Ergebnisliste an höherer Stelle als zuvor. In einzelnen Datensätzen ergaben sich sogar Verbesserungen von bis zu 50 Prozent. Dabei ließen sich vergleichbare Ergebnisse auch mit Artikeln erreichen, die nicht Teil der Optimierungsschleife waren (Cross-Validation).
Warum ist das relevant?
Für wissenschaftliche Infrastrukturen wie digitale Bibliotheken, Fachrepositorien oder Forschungsdatenplattformen ist es entscheidend, KI-Systeme effizient und ressourcenschonend betreiben zu können. Die Ergebnisse zeigen: Sinnvolle RAG-Optimierung ist auch ohne Rechenzentrum machbar.
Das senkt technische Hürden, reduziert Kosten und macht den Einsatz moderner KI-Technologien auch in kleineren Projekten realistisch.
Ausblick
Die für die Suche verwendeten Embedding-Vector-Modelle haben einen erheblichen Einfluss auf die Ergebnisse (vgl. Orbach et al. (2025)) und zwar sowohl auf die Rechenzeit als auch auf die Ergebnisqualität. Dabei zeigen Modelle nicht auf allen Datensätzen die gleichen Ergebnisse.
Es ist auch nur begrenzt möglich, die Optimierung mit extrem kleinen oder schnellen Embedding-Modellen auszuführen und die optimierten Parameter dann zusammen mit einem anderen, leistungsfähigen Modell im Live-Betrieb einzusetzen. Sind die eingesetzten Embedding-Modelle nicht angepasst genug an die verwendete Wissensdomäne, liefert auch die Optimierung nur suboptimale Ergebnisse.
Genau an diesem Punkt wird unsere Arbeit im Open Science Lab in der nächsten Zeit ansetzen. Gemeinsam mit den Fachinformationsdiensten FID Material Science, FID Move, FID Pyhsik und FID Philosophie evaluieren wir die Möglichkeit einer stärkeren Vernetzung von NFDI und FIDs mit dem Ziel, die einzelnen Wissendomänen mit fachspezifischen Embedding-Modellen zu versorgen. Zielsetzung ist es, damit den Zugang zu dieser Technologie noch weiter zu vereinfachen sowie die Qualität der Ergebnisse von KI-Anwendungen im Forschungs- und Bibliotheksumfeld gezielt zu erhöhen.
Prof. Dr. Ina Blümel, Open Science Lab // Foto: TIB/C. Bierwagen
„AutoRAG ist für uns ein wichtiger Innovationsschritt: Es macht RAG in offenen Wissensräumen wie Wikibase messbar, wiederholbar und mit überschaubaren Ressourcen betreibbar. Für Projekte wie NFDI4Culture und weitere Vorhaben im Open Science Lab bedeutet das spürbar bessere, nachvollziehbare KI-gestützte Suche über heterogene Bestände – ohne dass tiefes Spezial-Know-how aufgebaut werden muss. Nächster Schritt ist der Ausbau fachspezifischer Embeddings, kuratierter Testsets und transparenter Workflows, damit die Qualität und Nachnutzbarkeit langfristig steigt.“
Relevante Links
#NFDI4Culture #FID #FIDMove #SemanticMediawiki #FIDMaterialsScience #LizenzCCBY40INT #Wikibase #FIDPhysik #Projekte #RAG #KI