Tôi đã thực hiện dự án thú vị ở lớp cao học: tối ưu hóa mô hình Vision Transformer cho thiết bị biên (edge devices). Blog này chia sẻ kinh nghiệm triển khai, có thể hữu ích với những ai gặp khó khăn trong lĩnh vực này. 🚀 #AI #EdgeComputing #VisionTransformer #TríTuệNhânTạo #CôngNghệBiên
The unreasonable effectiveness of UNet for image segmentation?
I am focusing/fixating on segmentation models and the underlining principles I'd expect for computer (and human) vision.
1) I feel like UNet models shouldn't need all those skip-connections: the highest resolution one would do
2) I feel like the effectiveness comes from the decoder doing too much work, not only by receiving skip-connections but effectively adding many convolutions
3) I feel like fancier models that use transformer encoders UNet-like convolutional decoders incur in (2) and they're not particularly better/different
4) I think the encoder should do the heavy, semantic job; then a "pixel" would actually integrate information from its surroundings and a simple MLP decoder should suffice to classify/segment each pixel
The approaches in the biomedical field and in the industry of big players might be diverging, as Meta can use Segment Anything Model with heavy transformer encoder pretrained and trained on millions of images, while the avg biomed researcher may have some hundreds of samples and thus work at a scale where convolutional models are just better, and maybe where SAM can't be used.
LLMs like ChatGPT are based on Transformer AI models introduced 2017. Transformer was later also applied for computer vision with the introduction of self-supervised Vision Transformers.
If you want to know how ViTs work and what the uses cases are 👉 https://www.reply.com/en/artificial-intelligence/vision-transformers
#LLM #Chatgpt #gpt #AI #deeplearning #visiontransformer #computervision #CV


Big news in #EmbodiedAI by Meta! 🤯
VC-1 is an #AI visual cortex supporting sensorimotor skills, trained on the new Ego4D, it outperforms best-known results.
Adaptive Skill Coordination (ASC) achieves near-perfect performance on long-horizon tasks! 🤖
Of course we at Reply are already working on this with our fleet of robots. 😁
https://ai.facebook.com/blog/robots-learning-video-simulation-artificial-visual-cortex-vc-1/
#AI #deeplearning #computervision #AMR #robotics #robot #ML #visiontransformer #embodiment
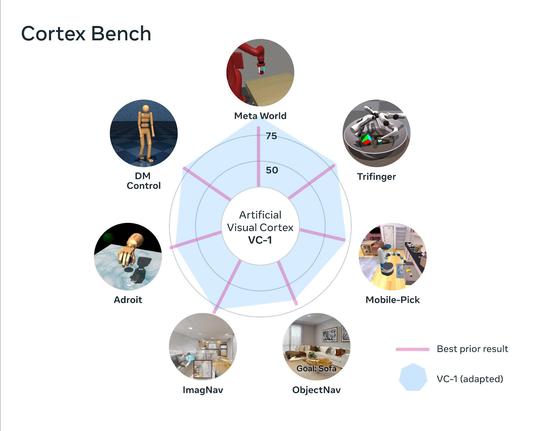
Robots that learn from human videos and simulated interactions
Training robots in the wild is slow, expensive, and dangerous. FAIR has developed an artificial visual cortex (VC-1) from egocentric videos and visuomotor skills from simulated environments that can form the foundation for embodied intelligence. VC-1 achieves impressive results on 17 different sensorimotor tasks in virtual environments, and the visuomotor skills deployed on the Spot robot achieve near-perfect performance on the task of navigating and fetching objects in indoor environments.