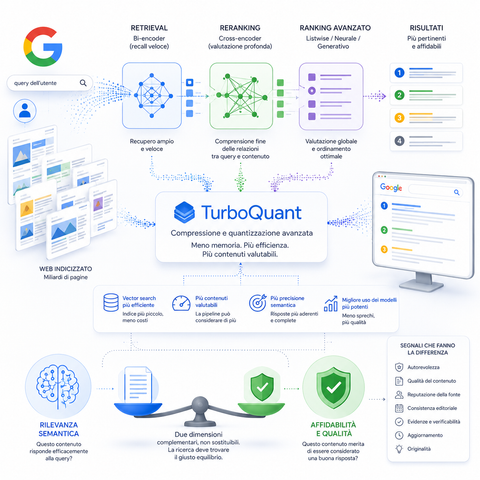
Google’s TurboQuant Crashed the AI Chip Market
A devastating blow to standard semiconductor hardware valuations. Google's unexpected mathematical optimization framework suddenly reduced the raw high-bandwidth memory overhead required to execute massive neural networks, instantly tanking physical graphics card demand and erasing billions in hardware equities.
#GoogleAI #TurboQuant #Semiconductors #TechFinance #HardwareMarket #MarketCrash
https://www.technology-news-channel.com/googles-turboquant-crashed-the-ai-chip-market/
A devastating blow to standard semiconductor hardware valuations. Google's unexpected mathematical optimization framework suddenly reduced the raw high-bandwidth memory overhead required to execute massive neural networks, instantly tanking physical graphics card demand and erasing billions in hardware equities.
#GoogleAI #TurboQuant #Semiconductors #TechFinance #HardwareMarket #MarketCrash
https://www.technology-news-channel.com/googles-turboquant-crashed-the-ai-chip-market/