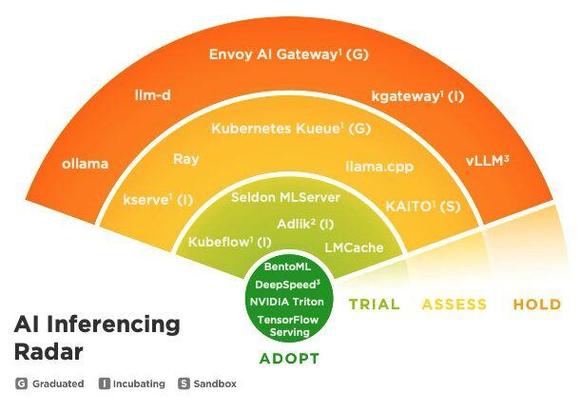
WOOT! #LMCache in the CNCF Technology Radar. https://cncf.io/reports/cncf-technology-landscape-radar/
That's golden to our community and everyone @tensormesh
#kubecon #cncf #AI #LLM #inference #Tensormesh
That's golden to our community and everyone @tensormesh
#kubecon #cncf #AI #LLM #inference #Tensormesh