LMCache 与 KV Cache 社区的新篇章
TL;DR: 作为 LMCache 社区的重要贡献者,Tensormesh 近期获得了一笔重大投资。这不仅是 Tensormesh 的重要里程碑,也将进一步推动 LMCache 社区实现共同使命:为每一位开发者打造最好的 KV cache library。 欢迎加入我们,与我们一起构建面向未来的 AI-native 数据层! KV Cache:正在成为独立的数据层...

LMCache 与 KV Cache 社区的新篇章
TL;DR: 作为 LMCache 社区的重要贡献者,Tensormesh 近期获得了一笔重大投资。这不仅是 Tensormesh 的重要里程碑,也将进一步推动 LMCache 社区实现共同使命:为每一位开发者打造最好的 KV cache library。 欢迎加入我们,与我们一起构建面向未来的 AI-native 数据层! KV Cache:正在成为独立的数据层...
LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and…
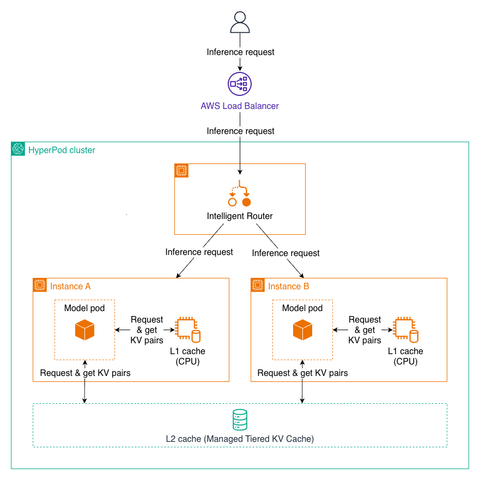
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
Accelerating OpenClaw Agents with CacheBlend
The standard approach to reducing LLM inference costs is prefix caching, which reuses previously computed token states to avoid redundant computation. In practice, however, this approach misses significant caching opportunities in real-world agentic workloads! Caching in Agentic Workflows In agentic workloads, shared content (e.g., retrieved contexts and documents) frequently appears across requests at varied positions,…
https://blog.lmcache.ai/en/2026/04/01/accelerating-openclaw-agents-with-cacheblend/

LMCache + NVIDIA Dynamo 1.0: A Match Made in Inference Heaven 🚀
We have some exciting news to share: NVIDIA Dynamo has officially hit v1.0, and we couldn't be more thrilled. This is a huge milestone for the LLM inference ecosystem and for us at LMCache, it's a moment worth celebrating. What Is NVIDIA Dynamo, and Why Does It Matter? If you haven't been following Dynamo's journey, here's the short version: …
https://blog.lmcache.ai/en/2026/03/16/lmcache-nvidia-dynamo-1-0-a-match-made-in-inference-heaven/

We have some exciting news to share: NVIDIA Dynamo has officially hit v1.0, and we couldn’t be more thrilled. This is a huge milestone for the LLM inference ecosystem and for us at LMCache, it’s a moment worth celebrating. What Is NVIDIA Dynamo, and Why Does It Matter? If you haven’t been following Dynamo’s journey, […]
LMCache Multi-node P2P CPU Memory Sharing & Control: From Experimental Feature to Production
Baolong Mao (Tencent), Chunxiao Zheng (Tencent), Weishu Deng (Tensormesh), Darren Peng (Tensormesh), Samuel Shen (Tensormesh) What is P2P and what does it promise? In this blog post, we will go over: a short motivation of the P2PBackend in LMCache and how it differs from existing KV Caching solutions how to run and benchmark performance on the P2PBackend design decisions and…

Baolong Mao (Tencent), Chunxiao Zheng (Tencent), Weishu Deng (Tensormesh), Darren Peng (Tensormesh), Samuel Shen (Tensormesh) What is P2P and what does it promise? In this blog post, we will go over: Most production vLLM deployments run multiple identical instances behind a load balancer. Each instance builds its own KV cache only from the traffic it […]
揭秘 Claude Code 底层的上下文工程与复用模式
过去几个月里,Claude Code 悄然成为了普通开发者可以使用的最有趣且被广泛采用的真实世界智能体(Agentic)系统之一。 它不同于那些内部机制隐藏在 API 网关之后的纯云端智能体(如 Perplexity、Devin 或 Manus),也不像完全的开源智能体(如 Mini SWE Agent 或 Terminus 2)那样你可以部署源代码。Claude Code 以部分本地的方式运行——它有一个运行在本地机器上的开源 客户端仓库。这给了我们一个难得的机会:通过注入并拦截它发送的流量来进行逆向工程,查看每一个 LLM 调用、每一次中间的工具调用,以及智能体做出的每一个微小决策。 最近,我们使用 Claude Code 进行了一次微型的单次实验(从 SWE-bench_Verified 数据集中随机选择了一个任务),并将所有内容捕获到一个仅包含 LLM 输入和输出的原始日志文件中:claude_code_trace.jsonl。如果你将 这个追踪文件 粘贴到…
LMCACHE:面向企业级大语言模型推理的高效KV Cache层
作者:Yihua Cheng 、Yuhan Liu 、 Jiayi Yao * 、Yuwei An、Xiaokun Chen、Shaoting Feng 、 Yuyang Huang、Samuel Shen、Kuntai Du、Junchen Jiang 单位:TensorMesh&芝加哥大学 摘要 如今的大语言模型(LLM)推理系统为简化设计,将各个推理引擎和请求独立处理,这导致了严重的资源效率低下问题。尽管已有相关方案提出通过跨请求复用KV Cache来避免冗余计算,并通过将单个请求拆分到不同推理引擎来提高 GPU 利用率,但这些方案的实现离不开 跨推理引擎与请求之间的高效KV Cache卸载和传输。本文提出 LMCACHE,首个且目前最高效的开源 KV Cache缓存解决方案。它能够提取并存储主流 LLM 推理引擎(vLLM 和 SGLang)生成的 KV Cache,并支持跨引擎、跨请求共享。LMCACHE 在 LLM 引擎接口中暴露 KV…
Tensormesh上线 & LMCache加入PyTorch Foundation
作者:Junchen Jiang 发布Tensormesh 首先我想要在这里重申一遍我上周在LMCache #general Slack频道中发布的一条新闻: “我非常高兴的宣布我们LMCache的创始团队已经在几个月前决定成立名为 Tensormesh 的公司。作为我们第一款产品 Beta 版本的发布,我们决定让Tensormesh正式亮相! 我们与公司同名的产品TensorMesh是一款 SaaS 前端,他允许您在我们所支持的不同硬件厂商的GPU上启动任何开源权重模型,同时对 LMCache 和 vLLM 进行参数自动调优以便在运行模型时提供最佳性能和成本节省。如果你想上手体验,点击这个链接在线注册。 前 100 名 Beta 测试者将在该平台获得 100 美元的 GPU 使用额度🔥🔥🔥 这对 LMCache 社区意味着什么?其实不应该被理解成一个大变动,因为 LMCache 依然是 Tensormesh…
LMCache Lab: 只针对prefilling阶段?我们把decoding阶段的延迟也省去60%!
() ( ( ( ( 作者:Kuntai Du 简要总结:🚀LMCache Lab 通过投机解码技术,将代码/文本编辑任务中的解码延迟降低了60%!⚡ --- 你可能是因为 KV cache优化而认识了 LMCache Lab——它让LLM的prefilling变得轻而易举。但这并不是全部!我们现在也专注于加速decoding阶段,让你的LLM智能体生成新内容的速度再上一个台阶。换句话说:在同样的工作量下,你可以少租几台机器,从而省下 LLM 服务的账单。🎉:money_with_wings: ## 我们在decoding阶段做了哪些优化? 我们发现,投机解码可以将代码和文本编辑任务中的token生成时间(即每个输出token的耗时)减少 60%!为什么?因为文本/代码编辑任务经常会复用已经存在的词组,而投机解码正是利用这一点来加速生成过程。放心——投机解码不会改变你的输出结果,只会让你更快得到它们! ##…
LMCache 第一时间支持 GPT-OSS(20B/120B)
() ( ( ( ( ( ( ( 作者:Yihua, Kobe LMCache 现已第一时间支持 OpenAI 最新发布的 GPT-OSS 模型(200 亿与 1200 亿参数)! 本文提供完整指南,教你如何用 vLLM + LMCache 部署 GPT-OSS 模型,并通过 CPU offloading能力获得显著性能提升。 ## 步骤 1:安装 vLLM GPT-OSS 版 ### 安装 ```bash uv pip install --pre vllm==0.10.1+gptoss \ --extra-index-url \ --extra-index-url \ --index-strategy unsafe-best-match ``` ### 验证安装 ```bash vllm serve openai/gpt-oss-120b --max-model-len 32768…





