New week, new slides: Run LLMs Locally
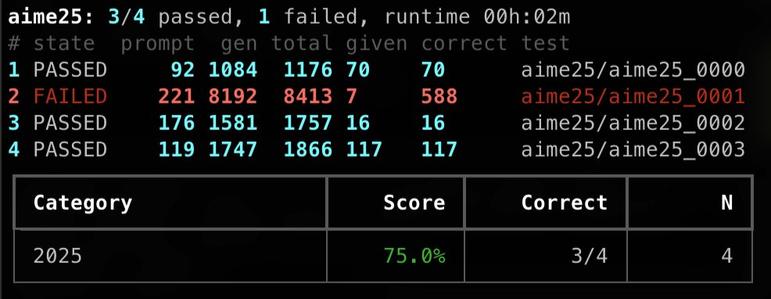
Now including multi-token prediction using Qwen3.6 35B-A3B with Nextn quantization. Also speech recognition using Qwen-3-ASR is now working directly with Llama.cpp and included in the slides.
https://codeberg.org/thbley/talks/raw/branch/main/Run_LLMs_Locally_2026_ThomasBley.pdf
#ai #llm #llamacpp #stablediffusion #qwen3 #glm #localai #gemma4 #webgpu #opencode #mtp