Ivan Fioravanti ᯅ (@ivanfioravanti)
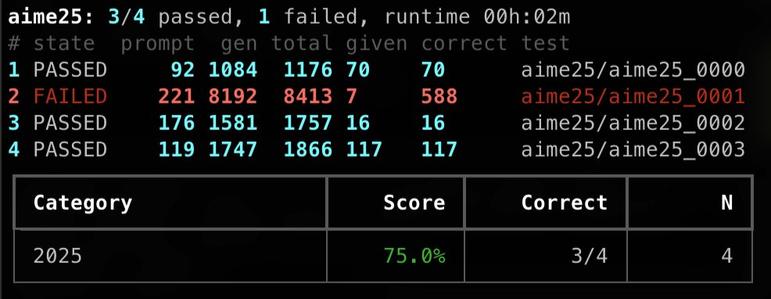
llama.cpp에서 Apple M5 환경의 추론/평가가 M3 Ultra나 M5 Max와 다르게 테스트 실패를 보이는 사례. 동일한 서버 설정과 temperature 0 조건에서도 재현되며, Apple GPU 계열에서의 안정성·일관성 문제를 시사하는 디버깅 이슈다.
Ivan Fioravanti ᯅ (@ivanfioravanti) on X
Llamacpp (9190) Inference on M5 (applegpu_g17s) <> M4 (applegpu_g16s) Here M5 run fails a test. Again temperature 0 and same server and evals used on M3 Ultra and M5 Max. llama-server -hf unsloth/Qwen3.6-35B-A3B-GGUF:UD-Q4_K_XL -ngl 99 -fa 1 -b 2048 -ub 2048 --cache-type-k