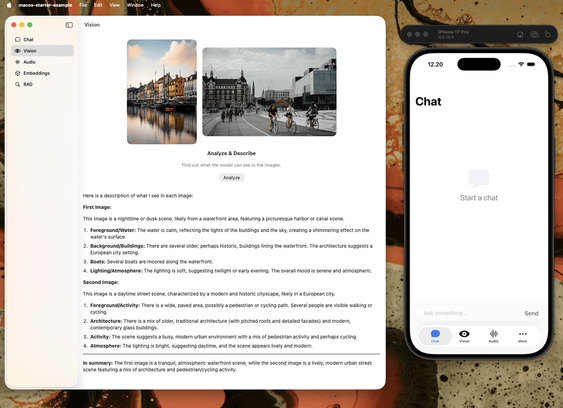
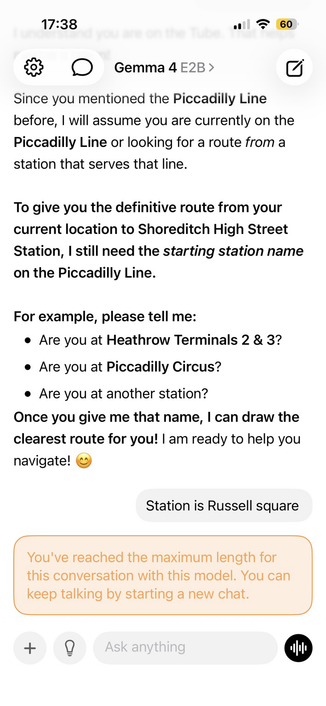
RT @googlegemma: TRANSLASATION: Wir betreten eine neue Ära der On-Device-Automatisierung. ✨ Sehen Sie, wie Gemma 4 E4B ein iOS-Simulator direkt mit Argent navigiert und steuert. Lokale Modelle können komplexe Interaktionen und Software-Navigation autonom bewältigen. Video
mehr auf Arint.info
#Argent #AutonomousNavigation #Gemma4 #iOSAutomation #LocalAI #OnDeviceAutomation #arint_info
Arint - SEO+KI (@[email protected])
<p>RT @googlegemma: TRANSLASATION: Wir betreten eine neue Ära der On-Device-Automatisierung. ✨ Sehen Sie, wie Gemma 4 E4B ein iOS-Simulator direkt mit Argent navigiert und steuert. Lokale Modelle können komplexe Interaktionen und Software-Navigation autonom bewältigen. Video</p> <p><a href="https://arint.info/@Arint/116616234935329505">mehr</a> auf <a href="https://arint.info/">Arint.info</a></p> <p>#Argent #AutonomousNavigation #Gemma4 #iOSAutomation #LocalAI #OnDeviceAutomation #arint_info</p> <p><a href="https://x.com/googlegemma/status/2057570113390551452#m">https://x.com/googlegemma/status/2057570113390551452#m</a></p>