A NVIDIA atualizou os valores da RTX Pro 6000 Ada Generation. O novo ajuste reflete mudanças no mercado de hardware de alta performance:
• Reajuste global de preços
• Foco em workflows profissionais
• Impacto direto no setor de IA e renderização
A NVIDIA atualizou os valores da RTX Pro 6000 Ada Generation. O novo ajuste reflete mudanças no mercado de hardware de alta performance:
• Reajuste global de preços
• Foco em workflows profissionais
• Impacto direto no setor de IA e renderização
Use your Nvidia GPU's VRAM as swap space on Linux
https://github.com/c0dejedi/nbd-vram
#HackerNews #NvidiaGPU #VRAM #LinuxSwap #GPUComputing #TechTips #OpenSource
Use your NVIDIA GPU's VRAM as swap space on Linux. Built for laptops with soldered memory and no upgrade path. If you have an RTX card sitting there with 8GB of VRAM and you're getting swap...
Running heavy AI workloads? 🧠 Standard CPUs won't cut it. Discover why Dedicated GPU Servers are essential for deep learning, offering unmatched power, top-tier security, and 100% exclusive resources over shared hosting. 🚀💻
Read More... https://www.ctcservers.com/blogs/ai-gpu-dedicated-servers/
#AI #MachineLearning #DedicatedServers #GPUComputing #ctcservers

Lilac - MLOps platform for distributed GPU workloads (@LilacML)
Cossmology Profile: https://dub.sh/iwaArlx
Key People: Ryan Ewing, Lucas Ewing

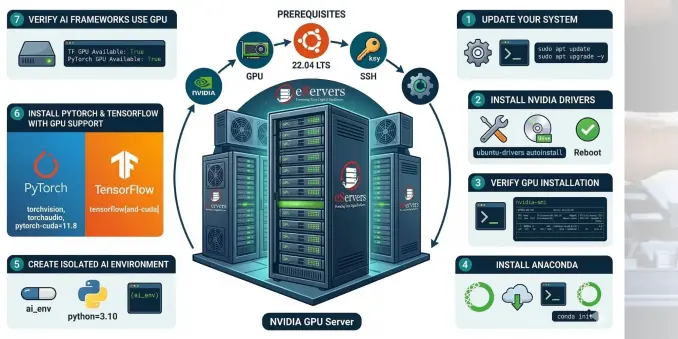
Setting up an AI/ML environment from scratch?
We just published a comprehensive 7-step guide on configuring an Ubuntu bare-metal NVIDIA GPU server.
We cover the exact bash commands for:
Installing proprietary NVIDIA drivers
Setting up Miniconda
Installing PyTorch & TensorFlow with full CUDA support
Read the full technical tutorial here:
https://www.eservers.uk/tutorials/howto/set-up-ai-ml-environment-gpu-server/
#MachineLearning #AI #PyTorch #TensorFlow #Ubuntu #Linux #DataScience #DevOps #GPUComputing #OpenSource
🔬 Breaking research shows how AI labs are revolutionizing computational efficiency! Token warehousing strategy could dramatically reduce GPU processing waste in large language models. Researchers uncover innovative techniques that might reshape machine learning infrastructure. Fascinating insights into cutting-edge AI optimization! #AI #MachineLearning #GPUComputing #LargeLanguageModels
🔗 https://aidailypost.com/news/ai-researchers-reveal-token-warehousing-strategy-cut-gpu

Người dùng đang tìm cách triển khai suy luận cục bộ cho mô hình lớn Qwen2.5-72B trên 2 GPU L40 (48GB VRAM mỗi chiếc) nhưng gặp trở ngại. Khi dùng Huggingface, quá trình bị treo, còn vLLM thì báo lỗi khởi tạo WorkerProc. Anh ấy đang tìm kiếm các gợi ý để giải quyết vấn đề phân chia mô hình và tăng tốc suy luận trên hệ thống đa GPU.
#LLM #AITech #vLLM #Huggingface #LocalInference #GPUComputing #Qwen2_5_72B
https://www.reddit.com/r/LocalLLaMA/comments/1q7gr9w/local_inference_with_big_model_shared_
