Lazy Pipelines, Fast Backends digs into how to keep data pipelines easy to write while still hitting serious performance in the backend.

Lazy Pipelines, Fast Backends digs into how to keep data pipelines easy to write while still hitting serious performance in the backend.
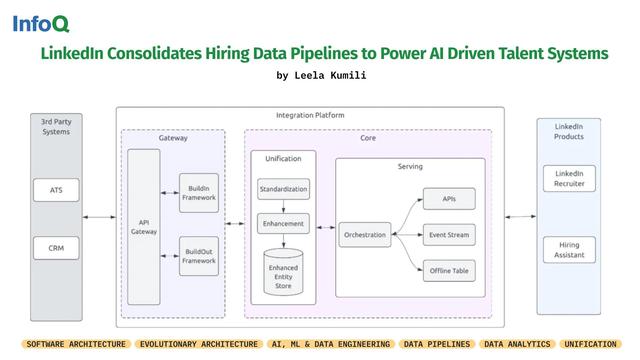
#LinkedIn has launched a unified integrations platform to standardize & reconcile hiring data across systems.
• 72% faster onboarding
• Improved data consistency and completeness
• Scalable AI-driven hiring enabled via standardized schemas, orchestration workflows, and centralized data processing
Learn more: https://bit.ly/48KFwof
#SoftwareArchitecture #EvolutionaryArchitecture #DataPipelines #DataAnalytics #InfoQ
#Confluent introduces a new approach in #ApacheKafka that moves schema IDs from message payloads to record headers.
✅ Simplify schema governance & evolution.
✅ Improve compatibility across serialization formats
✅ Reduce coupling between data & metadata in event-driven architectures
Read the deep dive on #InfoQ ⇨ https://bit.ly/4tF7Fot
#ML #EventStreamProcessing #ProtocolBuffers #DataPipelines #DataAnalytics

🎉 Milestone Unlocked: Finished the Data Engineering Zoomcamp!
In 10 weeks, I moved from scripting to architecting systems. We built real production-grade infrastructure using Spark, Kafka, Airflow, and Kestra—not just hobby projects.
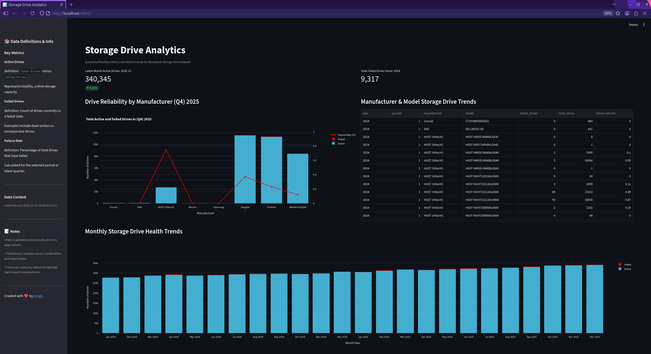
Capstone: A Storage Hard Drive Dashboard using real failure data from Backblaze
Stack: Terraform + Docker infra, Airflow orchestration, dbt modeling, Streamlit viz.
Key Lessons:
✅️ "It works on my laptop" isn't a strategy.
✅ Need IaC, partitioning, clustering, and strict error handling.
✅ dbt ensures reproducible, tested models.
✅ Infra is invisible work—if it breaks, your code fails.
Take the leap! It’s challenging but by week 10, pieces click into place. Seeing my pipeline run autonomously felt like crossing the finish line. 🏁
Thanks Data Talks Club team! On to the next challenge!
My project: https://github.com/ammartin8/hard_drive_analytics_dashboard
#mastodon #fediverse #data #spark #dataengineering #ai #technology #datatools #datapipelines #fedihire #thursday #sql #observability #etl #python #github
In this #InfoQ article, Vignesh Durai explains how agentic and multimodal AI systems can be engineered using #ApacheCamel & #LangChain4j.
The solution combines LLM-based reasoning, retrieval-augmented generation (RAG), and image classification.
🔗 Read now: https://bit.ly/4sXdlcM

Astro CLI Touts Agent-Ready Airflow Access
New Astro CLI feature lets agents control Airflow directly. See how this changes data workflows and what it means for developers starting 15 May 2024.
#AstroCLI, #AirflowAPI, #AIDataEngineering, #DevOps, #DataPipelines

Astro CLI now lets AI agents control Airflow directly, a big step from 15 May 2024. This is like giving robots the keys to manage complex data tasks.
#AstroCLI, #AirflowAPI, #AIDataEngineering, #DevOps, #DataPipelines
https://newsletter.tf/astro-cli-agent-airflow-api-access/
Diving deep into Spark batch processing!⚡️
Learned how to:
✅ Optimize data pipelines with filtering, repartitioning & grouping
✅ Design efficient ETL pipelines with Spark
✅ Understanding when and how to use partitioning strategies
✅ Use Google Cloud Storage (GCS) as a data source for Spark applications and configuring Spark to read Parquet or other formats from GCS
✅ Visualize execution plans for efficient coding
✅ Review the Spark UI for performance monitoring
💡 Key takeaway: One thing that amazes me about distributed computing is how we've transformed from struggling with massive datasets to generating insights in near real-time. As an analyst who has dealt with long wait times in processing data, spark saves so much time in getting results faster and make data-driven decisions more quickly.
Review my work here: https://github.com/ammartin8/data_engineering_zoom_camp/blob/main/modules/module_6/project_06/README.md
#mastodon #fediverse #data #spark #dataengineering #ai #technology #opensource #datatools #datapipelines #fedihire #wednesday #sql #observability #etl #python